
مقاله ای که مشاهده می کنید کار تیم هوش مصنوعی شرکت Meta است. ایده جالبی مطرح شده است که در ادامه مشاهده می فرمایید. در آخر نیز اصل مقاله را مثل همیشه برای دانلود در اختیار شما قرار دادیم.
عنوان: Agent Learning via Early Experience
نویسندگان: Kai Zhang و همکاران، Meta Superintelligence Labs، FAIR at Meta، The Ohio State University (2025)
🎯 مسئله
آموزش عاملهای زبانی (Language Agents) با یادگیری تقویتی دشوار است چون بسیاری از محیطها پاداش قابلاعتبار ندارند یا بازهی تصمیمگیری بسیار طولانی دارند. روش فعلی (یادگیری تقلیدی با دادهی انسانی) نیز گران، محدود و غیرقابل تعمیم است.
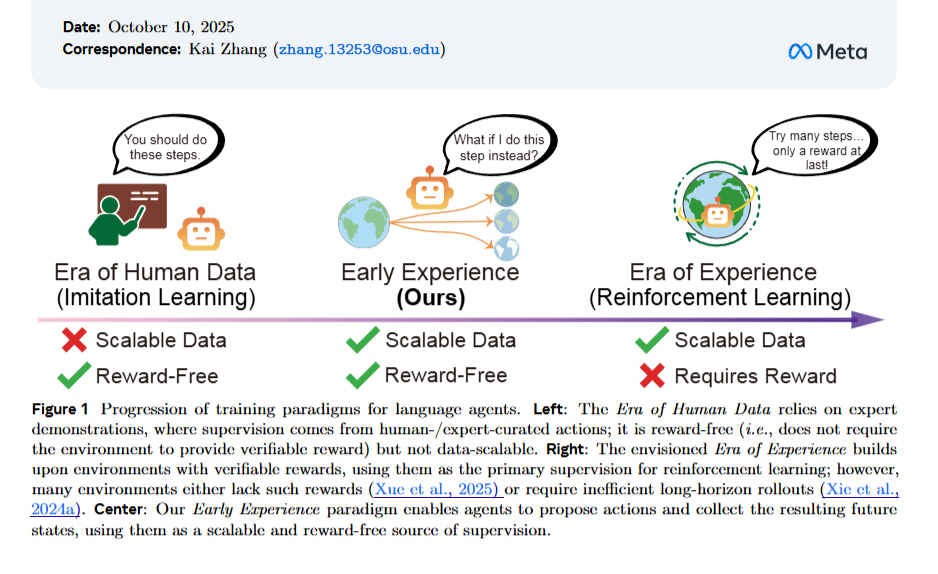
💡 ایدهی اصلی
ارائهی پارادایم جدیدی به نام “تجربهی اولیه (Early Experience)”
↳ حالتی میان یادگیری تقلیدی (Imitation Learning) و یادگیری تقویتی (Reinforcement Learning)
عامل با انجام عملهای خود و مشاهدهی وضعیتهای آینده (Future States) میآموزد؛
یعنی بدون پاداش بیرونی، از پیامد اعمال خودش یاد میگیرد.
.
⚙️ دو روش پیشنهادی
- Implicit World Modeling (مدلسازی ضمنی جهان):
عامل یاد میگیرد با پیشبینی وضعیت بعدی محیط، دینامیک محیط را درونی کند.
→ نوعی پیشآموزش سبک و مقاوم در برابر خطای توزیع. - Self-Reflection (خودبازنگری):
عامل با مقایسهی اعمال خود و عمل کارشناس، توضیح میدهد چرا عمل کارشناس بهتر است.
→ استدلال زبانی و تصحیح تصمیمهای اشتباه را یاد میگیرد.
💡آزمایشها
- روی ۸ محیط متنوع شامل ناوبری، استفاده از ابزار، وبگردی و برنامهریزی بلندمدت
- با سه مدل مختلف از خانوادههای Llama و Qwen
- شاخصها: نرخ موفقیت، تعمیم خارج از دامنه (OOD)، و بهبود پس از RL
.

📈 نتایج کلیدی
- میانگین بهبود نسبت به یادگیری تقلیدی:
+9.6٪ در موفقیت، +9.4٪ در تعمیم خارج از دامنه - بهکارگیری این روش قبل از RL باعث افزایش کارایی RL تا +6.4٪ شد.
- با نصف دادهی انسانی، عملکردی مشابه یا بهتر از حالت کامل حاصل شد.
- قابلگسترش در مدلهای بزرگ (تا 70B پارامتر).
.
🎯 جمعبندی و اهمیت
پارادایم تجربهی اولیه پلی میان دوران دادهی انسانی (Imitation Learning) و دوران تجربهی واقعی (Reinforcement Learning) است.
عامل میتواند بدون پاداش خارجی، از تجربیات خود یاد بگیرد و پایهای قوی برای یادگیری تقویتی آینده بسازد.
.
⚠️ محدودیتها و مسیر آینده
- هنوز محدود به تعاملات کوتاهمدت؛
- نیاز به گسترش برای ردیابی پاداشهای بلندمدت و یادگیری مداوم دارد؛
- آینده شامل ترکیب با اهداف خودنظارتی و انتقال بین محیطها خواهد بود.
.
دانلود کامل مقاله: