DeepSeek-OCR به عنوان یک مدل اولیه با امکان فشردهسازی متنهای طولانی از طریق نقشهبرداری بصری دوبعدی ارائه شد. DeepSeek-OCR از دو جزء تشکیل شده است: DeepEncoder و DeepSeek3B-MoE-A570M به عنوان رمزگشا(decoder). به طور خاص، DeepEncoder به عنوان موتور اصلی عمل میکند که برای حفظ فعالسازهای کم تحت ورودی با وضوح بالا و در عین حال دستیابی به نسبتهای فشردهسازی بالا برای اطمینان از تعداد بهینه و قابل مدیریت توکنهای بینایی طراحی شده است. آزمایشها نشان میدهد که وقتی تعداد توکنهای متنی در حدود 10 برابر توکنهای بینایی باشد (یعنی نسبت فشردهسازی < 10x)، مدل میتواند به دقت رمزگشایی (OCR) 97٪ دست یابد. حتی با نسبت فشردهسازی 20x، دقت OCR همچنان در حدود 60٪ باقی میماند. این امر نوید قابل توجهی برای زمینههای تحقیقاتی مانند فشردهسازی متنهای طولانی تاریخی و مکانیسمهای فراموشی حافظه در LLMها نشان میدهد.
فراتر از این، DeepSeek-OCR همچنین ارزش عملی بالایی را نشان میدهد. در OmniDocBench، این الگوریتم با استفاده از تنها ۱۰۰ توکن بینایی، از GOT-OCR2.0 (۲۵۶ توکن در هر صفحه) پیشی میگیرد و با استفاده از کمتر از ۸۰۰ توکن بینایی، از MinerU2.0 (به طور متوسط بیش از ۶۰۰۰ توکن در هر صفحه) نیز بهتر عمل میکند. در عمل، DeepSeek-OCR میتواند دادههای آموزشی را برای LLMها/VLMها در مقیاس ۲۰۰ هزار صفحه در روز (با پردازنده گرافیکی A100-40G ) تولید کند. کدها و وزنهای مدل در http://github.com/deepseek-ai/DeepSeek-OCR به صورت عمومی در دسترس هستند.
راه اندازی و استفاده
نصب
ابتدا مخزن گیت پروژه را از گیت هاب دریافت کنید و به پوشه DeepSeek-OCR بروید.
git clone https://github.com/deepseek-ai/DeepSeek-OCR.gitمحیط اجرا نیاز به cuda11.8+torch2.6.0 دارد
توصیه میشود از محیط conda برای محیط اجرای پروژه استفاده کنید
conda create -n deepseek-ocr python=3.12.9 -y
conda activate deepseek-ocrپکیج های مورد نیاز را نصب کنید.
ابتدا از آدرس زیر vllm 0.8.5 را بارگیری کنید
https://github.com/vllm-project/vllm/releases/tag/v0.8.5
سپس پکیج ها را با دستورات زیر نصب کنید
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118
pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl
pip install -r requirements.txt
pip install flash-attn==2.7.3 --no-build-isolationتوجه: اگر میخواهید کدهای vLLM و Transformers در یک محیط اجرا شوند، نیازی نیست نگران این خطای نصب مانند: vllm 0.8.5+cu118 requires
transformers>=4.51.1 باشید.
اجرا
اجرا با استفاده از vllm
نکته: تنظیمات INPUT_PATH/OUTPUT_PATH و سایر تنظیمات را در فایل DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py تغییر دهید.
cd DeepSeek-OCR-master/DeepSeek-OCR-vllmخروجی برای تصویر:
python run_dpsk_ocr_image.pyخروجی برای pdf با ۲۵۰۰ توکن بر ثانیه به صورت پردازش موازی(پردازنده گرافیکی A100-40G):
python run_dpsk_ocr_pdf.pyارزیابی دستهای برای معیارها:
python run_dpsk_ocr_eval_batch.pyکد مربوط به نسخه vLLM در [2025/10/23]
در ترمینال وارد کنید
uv venv
source .venv/bin/activate
# Until v0.11.1 release, you need to install vLLM from nightly build
uv pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
کد پایتون
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Create model instance
llm = LLM(
model="deepseek-ai/DeepSeek-OCR",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor]
)
# Prepare batched input with your image file
image_1 = Image.open("path/to/your/image_1.png").convert("RGB")
image_2 = Image.open("path/to/your/image_2.png").convert("RGB")
prompt = "<image>\nFree OCR."
model_input = [
{
"prompt": prompt,
"multi_modal_data": {"image": image_1}
},
{
"prompt": prompt,
"multi_modal_data": {"image": image_2}
}
]
sampling_param = SamplingParams(
temperature=0.0,
max_tokens=8192,
# ngram logit processor args
extra_args=dict(
ngram_size=30,
window_size=90,
whitelist_token_ids={128821, 128822}, # whitelist: <td>, </td>
),
skip_special_tokens=False,
)
# Generate output
model_outputs = llm.generate(model_input, sampling_param)
# Print output
for output in model_outputs:
print(output.outputs[0].text)اجرا با استفاده از transformers
استنتاج با استفاده از transformers (Huggingface ) در پردازندههای گرافیکی NVIDIA. الزامات روی پایتون ۳.۱۲.۹ + CUDA۱۱.۸ آزمایش شدند :
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)یا میتوانید از طریق زیر اجرا کنید
cd DeepSeek-OCR-master/DeepSeek-OCR-hf
python run_dpsk_ocr.pyحالت های پشتیبانی شده
مدل متن باز فعلی حالت های زیر را پشتیبانی میکند
- وضوح تصویر اصلی:
- کوچک: ۵۱۲×۵۱۲ (۶۴ توکن بینایی)✅
- کوچک: ۶۴۰×۶۴۰ (۱۰۰ توکن بینایی)✅
- پایه: ۱۰۲۴×۱۰۲۴ (۲۵۶ توکن بینایی)✅
- بزرگ: ۱۲۸۰×۱۲۸۰ (۴۰۰ توکن بینایی)✅
- وضوح تصویر پویا
- حالت گاندام: n×۶۴۰×۶۴۰ + ۱×۱۰۲۴×۱۰۲۴ ✅
نمونه پرامپت
با استفاده از نمونه پرامپت های زیر میتواند خروجی مطلوب خود را بدست آورید
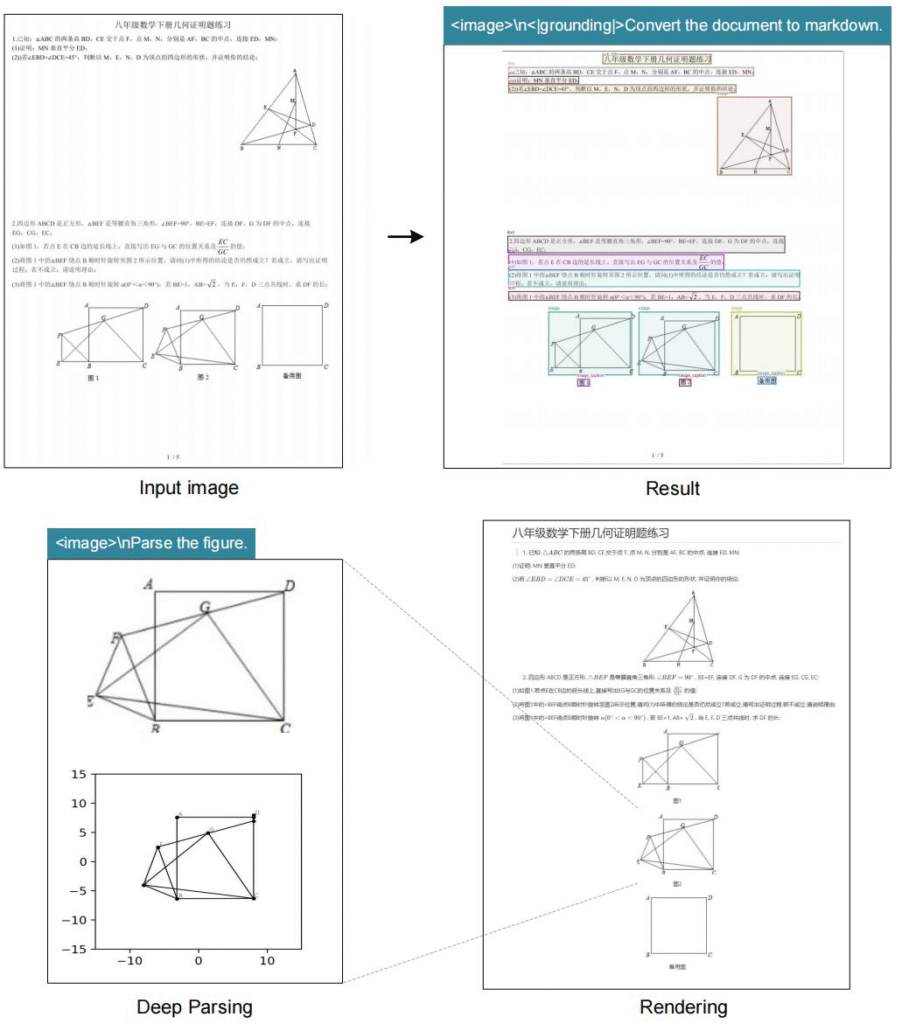
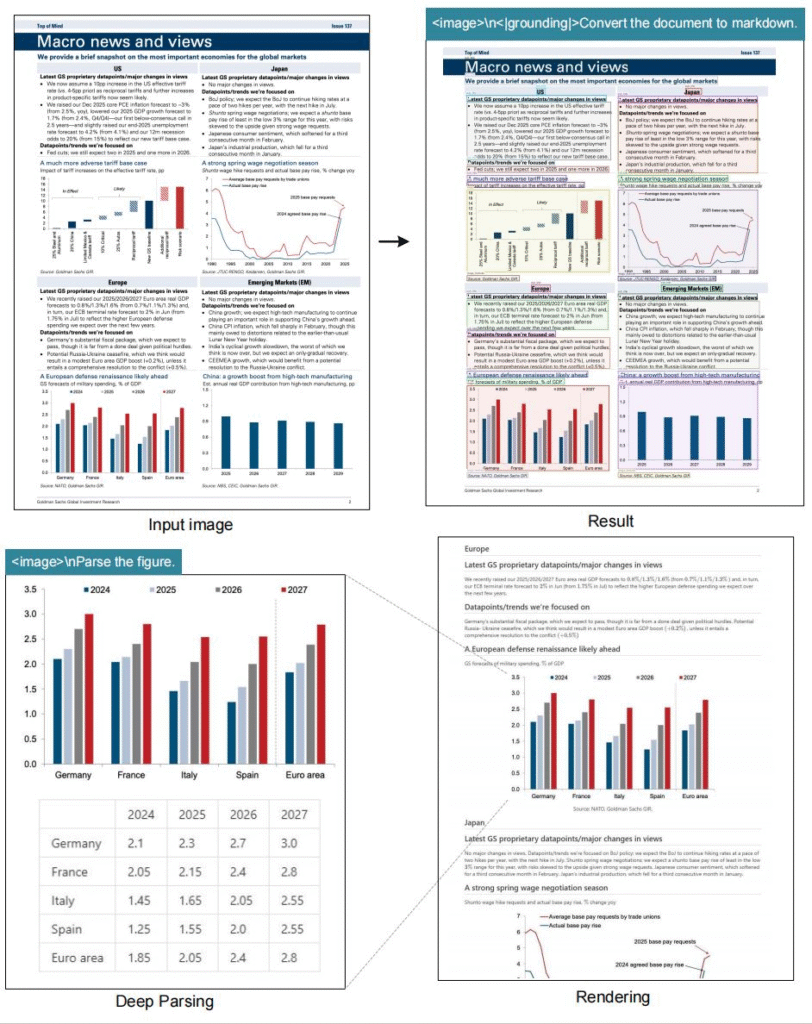
# document: <image>\n<|grounding|>Convert the document to markdown.
# other image: <image>\n<|grounding|>OCR this image.
# without layouts: <image>\nFree OCR.
# figures in document: <image>\nParse the figure.
# general: <image>\nDescribe this image in detail.
# rec: <image>\nLocate <|ref|>xxxx<|/ref|> in the image.
# '先天下之忧而忧'تصاویر نمونه