
Ling-1T اولین مدل پرچمدار غیرمتفکر(non-thinking model) در سری Ling 2.0 است که شامل ۱ تریلیون پارامتر کلی با تقریباً ۵۰ میلیارد پارامتر فعال در هر توکن است. Ling-1T که بر اساس معماری Ling 2.0 ساخته شده است، برای از بین بردن محدودیتهای استدلال کارآمد و شناخت مقیاسپذیر طراحی شده است.
Ling-1T-base که از قبل روی بیش از ۲۰ تریلیون توکن با کیفیت بالا و متراکم از استدلال آموزش دیده است، از طول متن تا ۱۲۸ هزار پشتیبانی میکند و یک فرآیند زنجیره فکری تکاملی (Evo-CoT یا Evolutionary of Chain-of-Thought ) را در اواسط آموزش و پس از آموزش اتخاذ میکند. این روش آموزش مدل، کارایی و عمق استدلال مدل را تا حد زیادی افزایش میدهد و به Ling-1T اجازه میدهد تا به عملکرد پیشرفته در چندین معیار استدلال پیچیده دست یابد به عبارت دیگر تعادل بین دقت و کارایی دارد.
استدلال کارآمد در سطح پرچمدار
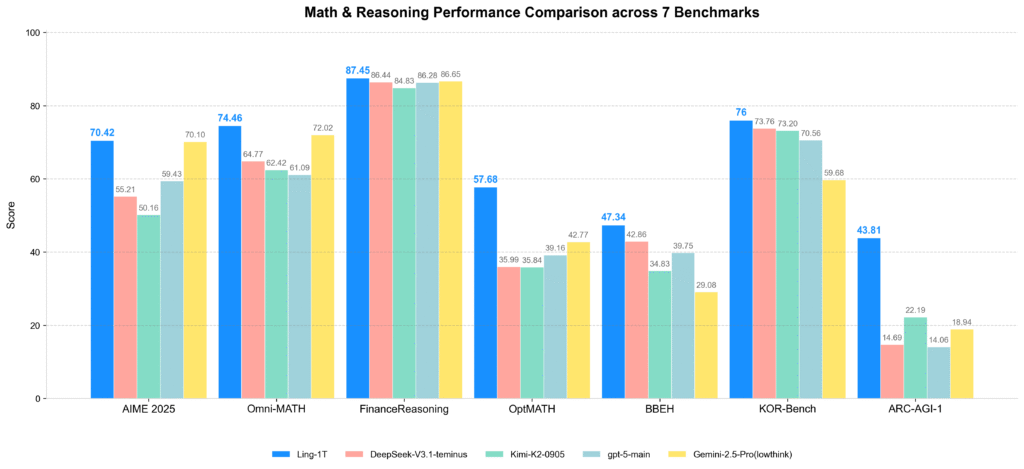
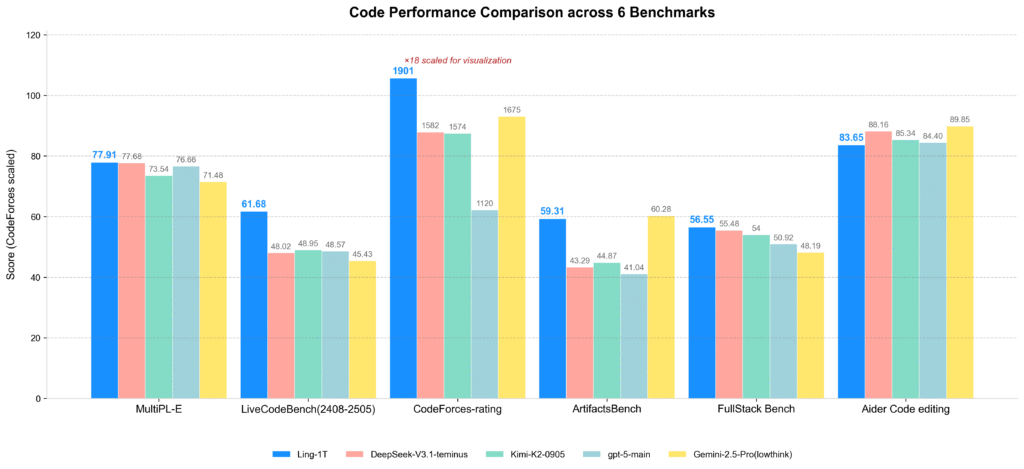
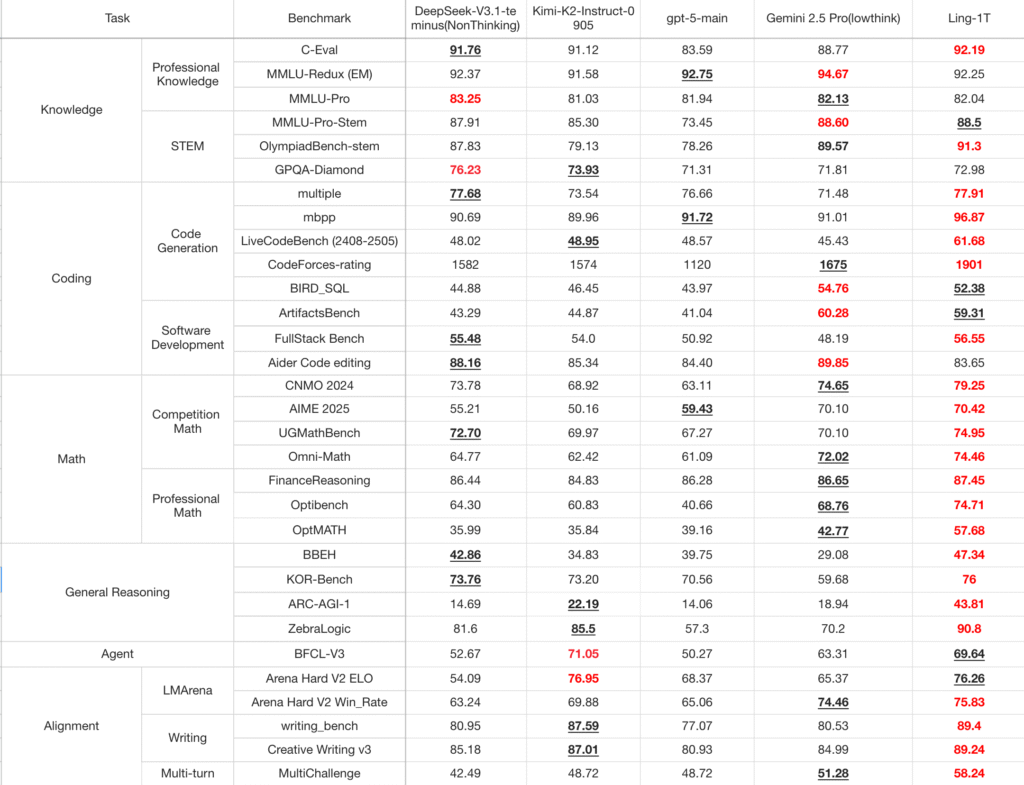
Ling-1T را به طور جامع در مقایسه با مدلهای پرچمدار پیشرو، از جمله مدل های بزرگ متنباز (مانند DeepSeek-V3.1-Terminus، Kimi-K2-Instruct-0905) و APIهای متنباز (GPT-5-main، Gemini-2.5-Pro) ارزیابی شده است. در زمینههای تولید کد، توسعه نرمافزار، ریاضیات در سطح رقابت و ریاضیات حرفهای و استدلال منطقی، Ling-1T به طور مداوم توانایی برتر در استدلال پیچیده و مزیت کلی را نشان میدهد.
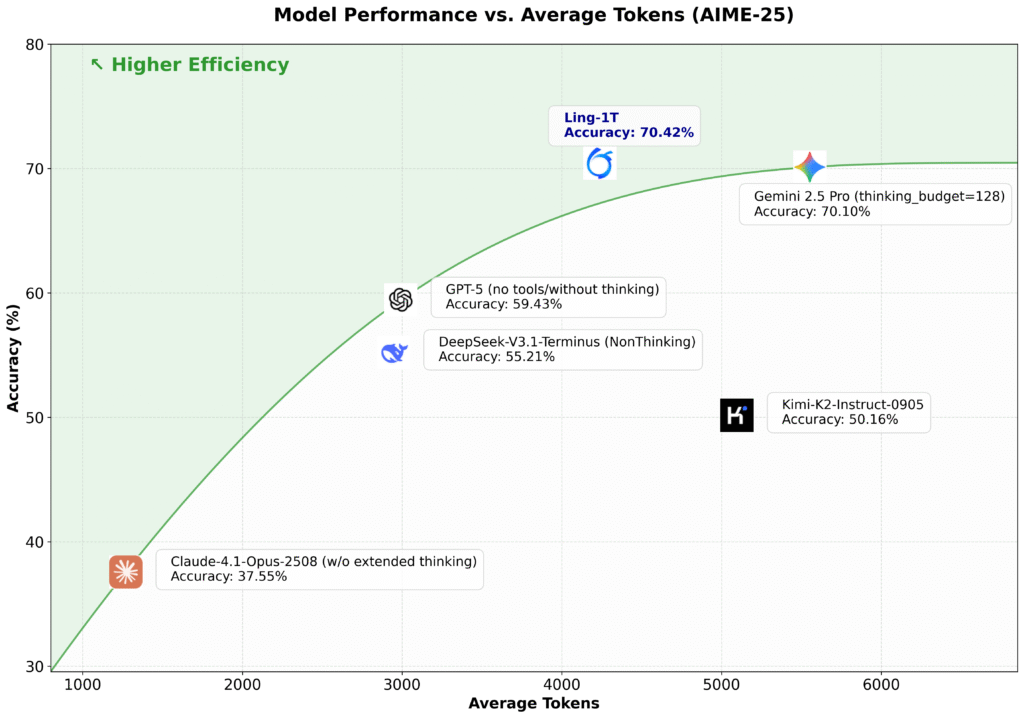
در معیار Ling-1T ،AIME 25 مرز پارتو (Pareto frontier) دقت استدلال در مقابل طول استدلال را گسترش میدهد و قدرت خود را در «تفکر کارآمد و استدلال دقیق» به نمایش میگذارد.
درک زیباییشناسی و تولید کد front-end
Ling-1T در استدلال بصری و وظایف تولید کد front-end عالی عمل میکند و درک معنایی عمیق را با تولید دقیق کد ترکیب میکند. این مدل یک مکانیسم پاداش ترکیبی نحوه عملکرد زیباییشناسی را معرفی میکند که مدل را قادر میسازد نه تنها کد صحیح و کاربردی تولید کند، بلکه حس زیباییشناسی بصری اصلاحشدهای را نیز نشان دهد. در Ling-1T ،ArtifactsBench در بین مدلهای متنباز رتبه اول را دارد و در واقع، رتبه بندی معیارها در این گزارش توسط خود Ling-1T تولید شدهاند.
هوش نوظهور در مقیاس میلیاردی
گسترش به سطح تریلیون پارامتر، قابلیتهای قوی استدلال نوظهور و انتقال را آشکار کرده است. به عنوان مثال، در معیار استفاده از ابزار BFCL V3مدل Ling-1T با تنظیم دستورالعملهای سبک، به دقت فراخوانی ابزار حدود ۷۰٪ دست مییابد – با وجود اینکه هیچ داده در مقیاس بزرگ در طول آموزش مشاهده نکرده است.
Ling-1T میتواند:
- دستورالعملهای پیچیده زبان طبیعی را تفسیر کند
- منطق انتزاعی را به اجزای بصری کاربردی تبدیل کند
- کد front-end سازگار با پلتفرمهای مختلف تولید کند
- متن بازاریابی و متن چندزبانه با سبک کنترلشده ایجاد کند
این قابلیتها، پایه و اساس هوش عمومی و مشارکتی انسان و هوش مصنوعی را تشکیل میدهند که هدف پیشرفت آن با همراهی جامعه متنباز از طریق انتشار Ling-1T است.
پیشآموزش در مقیاس تریلیون
معماری Ling 2.0 از پایه برای کارایی در مقیاس تریلیون طراحی شده است که توسط قانون مقیاسبندی Ling (arXiv:2507.17702) هدایت میشود. این امر مقیاسپذیری معماری و ابرپارامتر را حتی تحت 1e25-1e26 FLOP محاسباتی تضمین میکند.
نوآوریهای کلیدی معماری عبارتند از:
- 1T در مجموع / 50B پارامترهای فعال با نسبت MoE فعالسازی 1/32
- لایههای MTP برای استدلال ترکیبی بهبود یافته
- مسیریابی تخصصی بدون Auxiliary loss و امتیازدهی سیگموئید با بهروزرسانیهای میانگین صفر
- نرمالسازی QK(Query and Key) برای همگرایی کاملاً پایدار
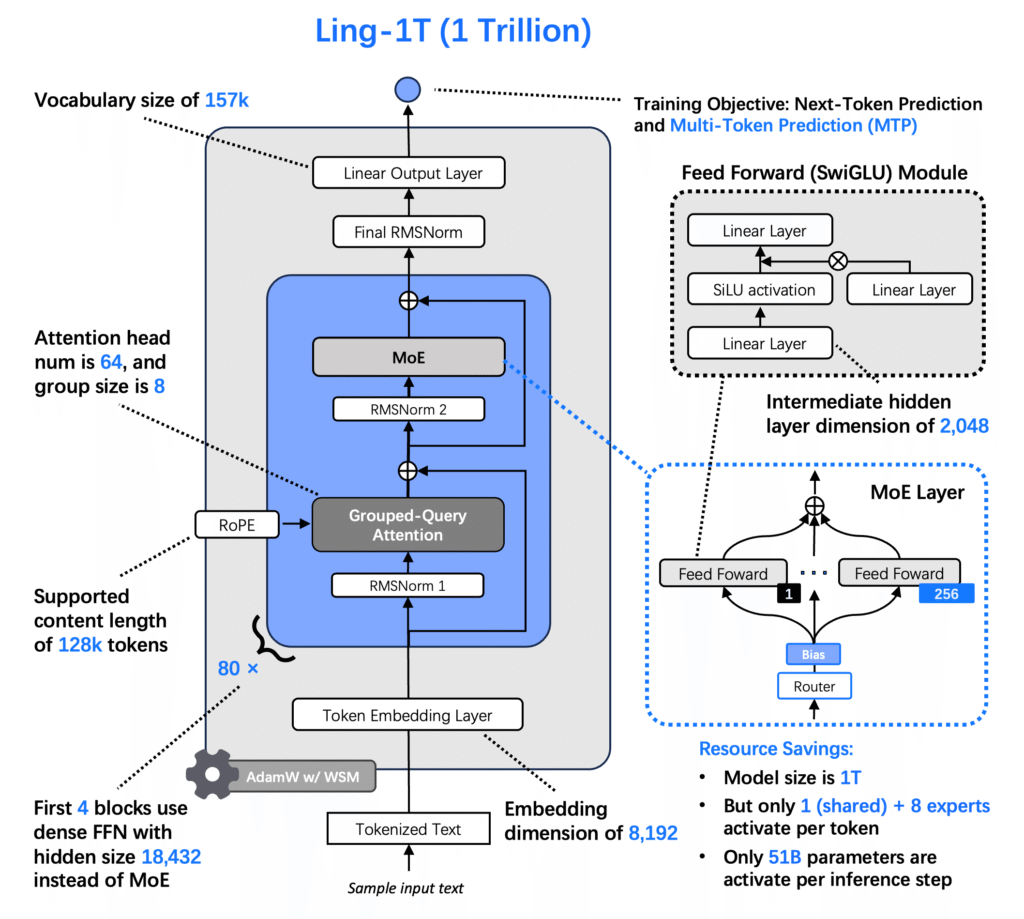
Ling-1T بزرگترین مدل بنیادی آموزشدیده با FP8 است که تا به امروز شناخته شده است. آموزش با دقت مختلط FP8 باعث افزایش سرعت تا ۱۵٪ و بهبود کارایی حافظه میشود و انحراف تلفات ≤ ۰.۱٪ از BF16 را در سراسر توکنهای ۱T حفظ میکند. یک pipeline درهمتنیده ۱F1B(one forward one backward) ریزدانه و ناهمگن که میزان استفاده را بیش از ۴۰٪ افزایش میدهد. بهینهسازیهای سطح سیستم شامل هستههای ترکیبی، زمانبندی ارتباطات، محاسبه مجدد، نقطه بازرسی، شبیهسازی و تلهمتری ، آموزش پایدار در مقیاس تریلیون را تضمین میکند.
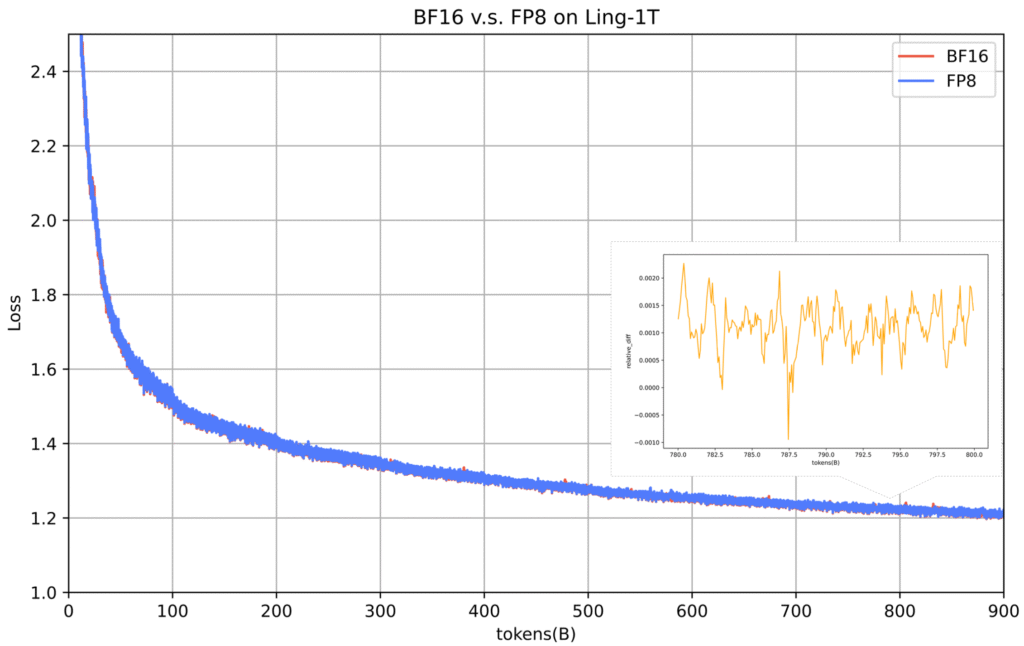
برای پیشآموزش از بیش از 20 ترابایت توکن با کیفیت بالا استفاده شده و در مراحل بعدی بیش از 40 درصد دادههای استدلال محور به کار برده شده است. در اواسط آموزش، پیکرههای زنجیره فکریِ گزینششده برای «پیشفعالسازی استدلال» معرفی شدند که پایداری استدلال در مراحل بعدی را بهبود میبخشد. یک زمانبندی LR (نرخ یادگیری) سفارشی WSM که مخفف Warmup–Stable–Merge (برای اطلاع بیشتر به (arXiv:2507.17634) مراجعه کنید) با ادغام checkpoint در اواسط آموزش، واپاشی LR را شبیهسازی کرده و تعمیمپذیری را افزایش میدهد.
بهینهسازی پس از آموزش و Evo-CoT
پس از آموزش که بر اساس فعالسازی استدلال در اواسط آموزش ساخته شده است، از Evo-CoT (زنجیره فکری تکاملی) برای بهبود تدریجی استدلال تحت هزینه(cost) قابل کنترل استفاده میکند. این رویکرد به طور مداوم مرز پارتو دقت استدلال در مقابل کارایی را گسترش میدهد که ایدهآل برای مدلهای غیرتفکری بازتابی(reflexive non-thinking models) است.
برای یادگیری تقویتی، ما LPO (بهینهسازی سیاست واحد زبانشناسی) را معرفی شده است که یک روش جدید بهینهسازی سیاست در سطح جمله میباشد. برخلاف الگوریتم بهینهسازی سیاست نسبی گروهی (Group Relative Policy Optimization یا به اختصار GRPO) در سطح توکن یا الکورتم بهینهسازی سیاست توالی گروهی (Group Sequence Policy Optimization یا به اختصار GSPO ) در سطح توالی، LPO با جملات به عنوان واحدهای عمل معنایی طبیعی رفتار میکند و امکان همترازی دقیق بین پاداشها و رفتار استدلال را فراهم میکند. از نظر تجربی، LPO پایداری آموزش و تعمیمپذیری برتر را در بین وظایف استدلال(reasoning) ارائه میدهد.
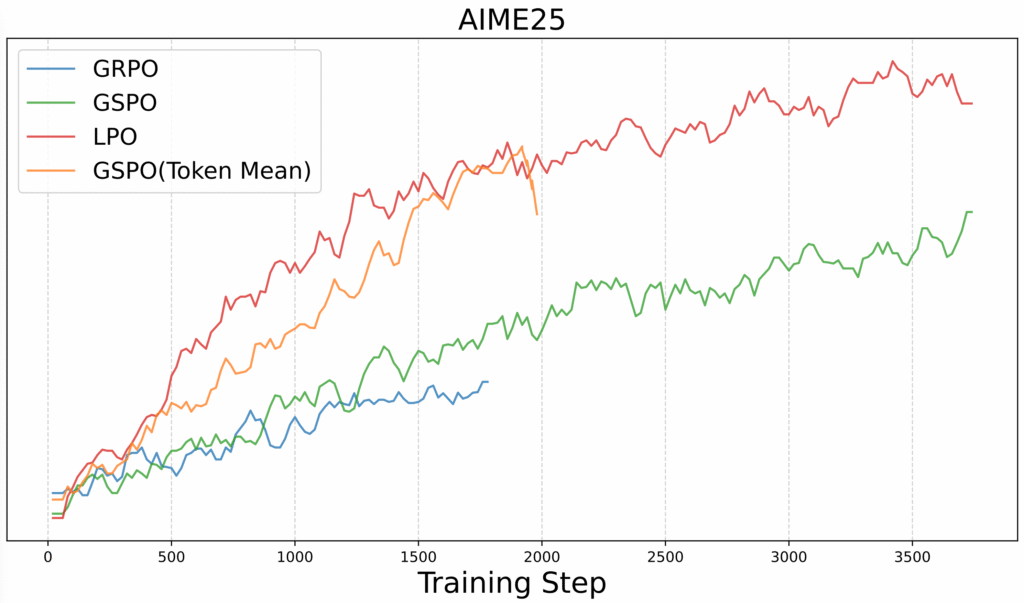
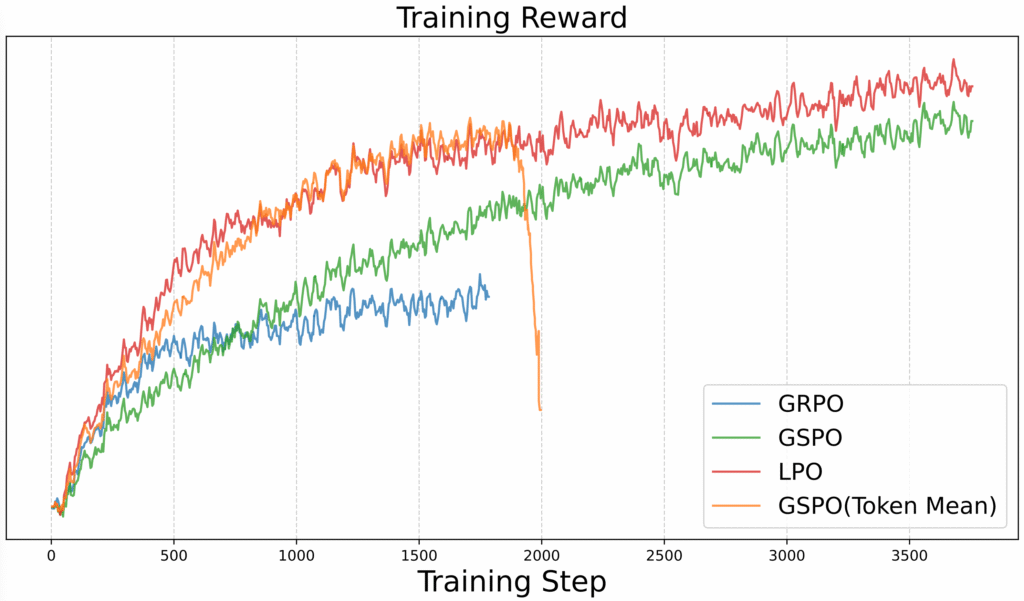
ارزیابی
Ling-1T به طور گسترده در معیارهای دانش، کد، ریاضی، استدلال، عامل و همترازی ارزیابی شده است. در حال حاضر به عنوان بهترین مدل پرچمدار متنباز غیرتفکری شناخته میشود که در استدلال پیچیده با APIهای متنباز رقابت میکند و در عین حال کارایی و تفسیرپذیری فوقالعادهای را حفظ میکند.
دانلود مدل
شما میتوانید Ling-1T را از جدول زیر دانلود کنید.
| مدل | طول متن | آدرس دانلود |
|---|---|---|
| Ling-1T | 32K -> 128K (YaRN) | https://huggingface.co/inclusionAI/Ling-1T |
استفاده سریع
🚀 اجرای آنلاین
میتوانید Ling-1T را به صورت آنلاین در ZenMux در آدرس زیر تجربه کنید
https://zenmux.ai/inclusionai/ling-1t?utm_source=hf_inclusionAI
🔌 استفاده از API
همچنین میتوانید از طریق فراخوانیهای API از Ling-1T استفاده کنید:
from openai import OpenAI
# 1. Initialize the OpenAI client
client = OpenAI(
# 2. Point the base URL to the ZenMux endpoint
base_url="https://zenmux.ai/api/v1",
# 3. Replace with the API Key from your ZenMux user console
api_key="<your ZENMUX_API_KEY>",
)
# 4. Make a request
completion = client.chat.completions.create(
# 5. Specify the model to use in the format "provider/model-name"
model="inclusionai/ling-1t",
messages=[
{
"role": "user",
"content": "What is the meaning of life?"
}
]
)
print(completion.choices[0].message.content)استقرار
SGLang
آمادهسازی محیط اجرا
میتوان با دنبال کردن این مراحل، محیط اجرا را آماده نمود:
pip3 install -U sglang sgl-kernelاجرای مدل
هر دو مدل BF16 و FP8 توسط SGLang پشتیبانی میشوند. این به نوع داده مدل در {MODEL_PATH} بستگی دارد.
در اینجا مثالی برای اجرای Ling-1T با چندین گره GPU وجود دارد، که در آن IP گره اصلی {MASTER_IP} و پورت سرور {PORT} است:
- سرور
# Node 0:
python -m sglang.launch_server --model-path $MODEL_PATH --tp-size 8 --pp-size 4 --dp-size 1 --trust-remote-code --dist-init-addr $MASTER_IP:2345 --port $PORT --nnodes 4 --node-rank 0
# Node 1:
python -m sglang.launch_server --model-path $MODEL_PATH --tp-size 8 --pp-size 4 --dp-size 1 --trust-remote-code --dist-init-addr $MASTER_IP:2345 --port $PORT --nnodes 4 --node-rank 1
# Node 2:
python -m sglang.launch_server --model-path $MODEL_PATH --tp-size 8 --pp-size 4 --dp-size 1 --trust-remote-code --dist-init-addr $MASTER_IP:2345 --port $PORT --nnodes 4 --node-rank 2
# Node 3:
python -m sglang.launch_server --model-path $MODEL_PATH --tp-size 8 --pp-size 4 --dp-size 1 --trust-remote-code --dist-init-addr $MASTER_IP:2345 --port $PORT --nnodes 4 --node-rank 3
این فقط یک مثال است. لطفاً آرگومانها را مطابق با محیط واقعی خود تنظیم کنید.
- کلاینت
curl -s http://${MASTER_IP}:${PORT}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "auto", "messages": [{"role": "user", "content": "What is the capital of France?"}]}'برای موارد استفاده بیشتر به لینک زیر مراجعه نمایید
https://docs.sglang.ai/basic_usage/send_request.html
vLLM
آماده سازی محیط اجرا
pip install vllm==0.11.0
اجرای مدل
در اینجا مثالی برای استقرار مدل با چندین گره GPU آورده شده است، که در آن IP گره اصلی {MASTER_IP}، پورت سرور {PORT} و مسیر مدل {MODEL_PATH} است:
# step 1. start ray on all nodes
# step 2. start vllm server only on node 0:
vllm serve $MODEL_PATH --port $PORT --served-model-name my_model --trust-remote-code --tensor-parallel-size 8 --pipeline-parallel-size 4 --gpu-memory-utilization 0.85این فقط یک مثال است. لطفاً آرگومانها را مطابق با محیط واقعی خود تنظیم کنید.
برای مدیریت متن طولانی در vLLM با استفاده از YaRN، باید این دو مرحله را دنبال کنیم:
- یک فیلد rope_scaling به فایل config.json مدل اضافه کنید، برای مثال:
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
- از یک پارامتر اضافی –max-model-len برای مشخص کردن حداکثر طول متن مورد نظر هنگام شروع سرویس vLLM استفاده کنید.
برای راهنمایی دقیق، لطفاً به دستورالعملهای vLLM مراجعه کنید.
https://docs.vllm.ai/en/latest
محدودیتها و برنامههای آینده
در حالی که Ling-1T پیشرفت چشمگیری در استدلال کارآمد، تعمیم بین دامنهای و کارایی آموزش داشته است، چندین محدودیت همچنان باقی مانده است:
- توجه مبتنی بر GQA(Grouped query attention): برای استدلال در زمینههای طولانی پایدار است اما نسبتاً پرهزینه است. نسخههای آینده برای بهبود کارایی، توجه ترکیبی را اتخاذ خواهند کرد.
- توانایی عامل محدود: مدل فعلی جای رشد در تعامل چند نوبتی، حافظه بلندمدت و استفاده از ابزار را دارد.
- مشکلات دستورالعمل و هویت: ممکن است گاهی اوقات انحراف یا سردرگمی نقش رخ دهد؛ بهروزرسانیهای آینده، همترازی و سازگاری را افزایش میدهند.
نسخههای آینده Ling-1T به تکامل در معماری، استدلال و همترازی ادامه خواهند داد و این مجموعه را به سمت هوش عمومیتر پیش خواهند برد.