
MiniMax-M2 کارایی را برای عاملها از نو تعریف میکند. این یک مدل MoE فشرده، سریع و مقرونبهصرفه (۲۳۰ میلیارد پارامتر در کل با ۱۰ میلیارد پارامتر فعال) است که برای عملکرد عالی در کدنویسی و وظایف عاملمحور ساخته شده است، در عین حال هوش عمومی قدرتمندی میباشد. MiniMax-M2 با تنها ۱۰ میلیارد پارامتر فعال، عملکرد پیچیده و جامعی را که از مدلهای پیشرو امروزی انتظار میرود، ارائه میدهد، اما در یک فرم فاکتور ساده که استقرار و مقیاسپذیری را آسانتر از همیشه میکند.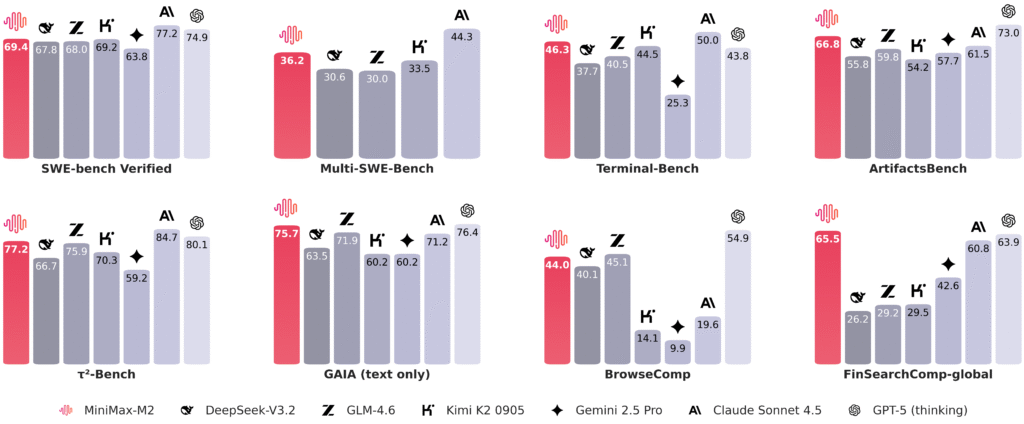
نکات برجسته
هوش برتر. طبق معیارهای تحلیل هوش مصنوعی، MiniMax-M2 هوش عمومی بسیار رقابتی را در ریاضیات، علوم، دنبال کردن دستورالعملها، کدنویسی و استفاده از ابزارهای عامل نشان میدهد. امتیاز ترکیبی آن در بین مدلهای منبع باز در سطح جهانی رتبه ۱ را دارد.
کدنویسی پیشرفته. MiniMax-M2 که برای گردشهای کاری توسعهدهندگان به طور سرتاسری طراحی شده است، در ویرایشهای چند فایلی، حلقههای کدنویسی، اجرا، رفع و تعمیرات (اعتبارسنجی شده توسط تست)، عالی عمل میکند. عملکرد قوی در وظایف به سبک Terminal-Bench و (Multi-)SWE-Bench، اثربخشی عملی را در ترمینالها، IDEها و CI در زبانهای مختلف نشان میدهد.
عملکرد عامل. MiniMax-M2 زنجیره ابزارهای پیچیده و بلندمدت را در ترمینال، مرورگر، بازیابی و اجراکنندههای کد برنامهریزی و اجرا میکند. در ارزیابیهای به سبک BrowseComp، به طور مداوم منابع دشوار را پیدا میکند، شواهد را قابل ردیابی نگه میدارد و به طرز زیبایی از مراحل ناهموار بازیابی میکند.
طراحی کارآمد. با 10 میلیارد پارامتر فعال (در مجموع 230 میلیارد)، MiniMax-M2 تأخیر کمتر، هزینه کمتر و توان عملیاتی بالاتری را برای عاملهای تعاملی و نمونهبرداری دستهای ارائه میدهد. کاملاً همسو با تغییر به سمت مدلهای بسیار قابل استقرار که هنوز در کدنویسی و وظایف عاملمحور میدرخشند.
معیارهای کدنویسی و عاملمحور
این ارزیابیهای جامع، کدنویسی سرتاسری و استفاده از ابزار عاملمحور را در دنیای واقعی آزمایش میکنند که شامل موارد زیر میباشد :
- ویرایش مخازن واقعی
- اجرای دستورات
- مرور وب
- ارائه راهحلهای کاربردی.
عملکرد در این مجموعه با تجربه روزمره توسعهدهندگان در ترمینالها، IDEها و CI مرتبط است.
| Benchmark | MiniMax-M2 | Claude Sonnet 4 | Claude Sonnet 4.5 | Gemini 2.5 Pro | GPT-5 (thinking) | GLM-4.6 | Kimi K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 69.4 | 72.7 * | 77.2 * | 63.8 * | 74.9 * | 68 * | 69.2 * | 67.8 * |
| Multi-SWE-Bench | 36.2 | 35.7 * | 44.3 | / | / | 30 | 33.5 | 30.6 |
| SWE-bench Multilingual | 56.5 | 56.9 * | 68 | / | / | 53.8 | 55.9 * | 57.9 * |
| Terminal-Bench | 46.3 | 36.4 * | 50 * | 25.3 * | 43.8 * | 40.5 * | 44.5 * | 37.7 * |
| ArtifactsBench | 66.8 | 57.3* | 61.5 | 57.7* | 73* | 59.8 | 54.2 | 55.8 |
| BrowseComp | 44 | 12.2 | 19.6 | 9.9 | 54.9* | 45.1* | 14.1 | 40.1* |
| BrowseComp-zh | 48.5 | 29.1 | 40.8 | 32.2 | 65 | 49.5 | 28.8 | 47.9* |
| GAIA (text only) | 75.7 | 68.3 | 71.2 | 60.2 | 76.4 | 71.9 | 60.2 | 63.5 |
| xbench-DeepSearch | 72 | 64.6 | 66 | 56 | 77.8 | 70 | 61 | 71 |
| HLE (w/ tools) | 31.8 | 20.3 | 24.5 | 28.4 * | 35.2 * | 30.4 * | 26.9 * | 27.2 * |
| τ²-Bench | 77.2 | 65.5* | 84.7* | 59.2 | 80.1* | 75.9* | 70.3 | 66.7 |
| FinSearchComp-global | 65.5 | 42 | 60.8 | 42.6* | 63.9* | 29.2 | 29.5* | 26.2 |
| AgentCompany | 36 | 37 | 41 | 39.3* | / | 35 | 30 | 34 |
نکات: نقاط دادهای که با ستاره (*) مشخص شدهاند، مستقیماً از گزارش یا وبلاگ رسمی فنی مدل گرفته شدهاند. سایر معیارها با استفاده از روشهای ارزیابی شرح داده شده در زیر به دست آمدهاند.
- SWE-bench Verified: در اینجا از همان چارچوب R2E-Gym (Jain et al. 2025) در بالای OpenHands برای آزمایش با عاملها در وظایف SWE استفاده شده است. همه امتیازات در زیرساخت داخلی با طول متن ۱۲۸ کیلوبایتی، حداکثر ۱۰۰ مرحله و بدون مقیاسبندی زمان آزمون، اعتبارسنجی میشوند. تمام محتوای مربوط به git حذف میشود تا اطمینان حاصل شود که عامل فقط کد را در نقطه مشکل میبیند.
- SWE-Bench چندگانه و SWE-bench چندزبانه: همه امتیازات در ۸ اجرا با استفاده از CLI کد claude (حداکثر ۳۰۰ مرحله) به عنوان چارچوب ارزیابی، میانگینگیری میشوند.
- Terminal-Bench: همه امتیازات با کد claude رسمی از مخزن اصلی Terminal-Bench (commit 94bf692) ارزیابی میشوند و میانگینگیری آنها در ۸ اجرا برای گزارش میانگین نرخ قبولی انجام میشود.
- ArtifactsBench: همه امتیازات با میانگینگیری سه اجرا با پیادهسازی رسمی ArtifactsBench، با استفاده از مدل پایدار Gemini-2.5-Pro به عنوان مدل قضاوت محاسبه میشوند.
- BrowseComp و BrowseComp-zh و GAIA (فقط متن) و xbench-DeepSearch: همه امتیازات گزارششده از همان چارچوب عامل WebExplorer (Liu et al. 2025) استفاده میکنند، با کمی تنظیم توضیحات ابزار. از زیرمجموعه اعتبارسنجی GAIA فقط متنی ۱۰۳ نمونهای با پیروی از WebExplorer (Liu et al. 2025) به کار گرفته شده است.
- HLE (با ابزارها): همه امتیازات گزارششده با استفاده از ابزارهای جستجو و یک ابزار پایتون به دست میآیند. ابزارهای جستجو از همان چارچوب عامل WebExplorer (Liu et al. 2025) استفاده میکنند و ابزار پایتون در یک محیط Jupyter اجرا میشود. از زیرمجموعه HLE فقط متنی استفاده شده است.
- τ²-Bench: تمام نمرات گزارششده از «تفکر توسعهیافته با استفاده از ابزار» استفاده میکنند و از GPT-4.1 به عنوان شبیهساز کاربر استفاده میکنند.
- FinSearchComp-global: نتایج رسمی برای GPT-5-Thinking، Gemini 2.5 Pro و Kimi-K2 گزارش شده است. سایر مدلها با استفاده از چارچوب متنباز FinSearchComp (Hu et al. 2025) با استفاده از ابزارهای جستجو و پایتون که به طور همزمان برای سازگاری راهاندازی شدهاند، ارزیابی میشوند.
- AgentCompany: تمام نمرات گزارششده از چارچوب عامل OpenHands 0.42 استفاده میکنند.
معیارهای هوشمندی
این مدل با تحلیل مصنوعی همسو است به طوری که معیارهای چالشبرانگیز را با استفاده از یک روششناسی منسجم جمعآوری میکند تا نمایه هوش گستردهتر مدل را در ریاضی، علوم، دنبال کردن دستورالعمل، کدنویسی و استفاده از ابزار عامل منعکس کند.
| Metric (AA) | MiniMax-M2 | Claude Sonnet 4 | Claude Sonnet 4.5 | Gemini 2.5 Pro | GPT-5 (thinking) | GLM-4.6 | Kimi K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|---|---|
| AIME25 | 78 | 74 | 88 | 88 | 94 | 86 | 57 | 88 |
| MMLU-Pro | 82 | 84 | 88 | 86 | 87 | 83 | 82 | 85 |
| GPQA-Diamond | 78 | 78 | 83 | 84 | 85 | 78 | 77 | 80 |
| HLE (w/o tools) | 12.5 | 9.6 | 17.3 | 21.1 | 26.5 | 13.3 | 6.3 | 13.8 |
| LiveCodeBench (LCB) | 83 | 66 | 71 | 80 | 85 | 70 | 61 | 79 |
| SciCode | 36 | 40 | 45 | 43 | 43 | 38 | 31 | 38 |
| IFBench | 72 | 55 | 57 | 49 | 73 | 43 | 42 | 54 |
| AA-LCR | 61 | 65 | 66 | 66 | 76 | 54 | 52 | 69 |
| τ²-Bench-Telecom | 87 | 65 | 78 | 54 | 85 | 71 | 73 | 34 |
| Terminal-Bench-Hard | 24 | 30 | 33 | 25 | 31 | 23 | 23 | 29 |
| AA Intelligence | 61 | 57 | 63 | 60 | 69 | 56 | 50 | 57 |
AA: تمام امتیازات MiniMax-M2 با روششناسی معیار هوش مصنوعی (https://artificialanalysis.ai/methodology/intelligence-benchmarking) همسو هستند. تمام امتیازات سایر مدلها از https://artificialanalysis.ai گزارش شدهاند.
اهمیت اندازه فعالسازی
با حفظ فعالسازیها در حدود 10B، حلقه plan → act → verify در گردش کار agentic سادهسازی میشود، که باعث بهبود پاسخگویی و کاهش سربار محاسباتی میشود:
- چرخههای بازخورد سریعتر در زنجیرههای compile-run-test و browse-retrieve-cite.
- اجراهای همزمان بیشتر با بودجه یکسان برای مجموعههای رگرسیون و کاوشهای چند مرحلهای.
- برنامهریزی ظرفیت سادهتر با حافظه کمتر برای هر درخواست و تأخیر پایدارتر موارد خاص.
به طور خلاصه: فعالسازیهای 10B = حلقههای عامل پاسخگو + واحد اقتصادی بهتر.
در یک نگاه
اگر به کدنویسی به سبک مرزی و عاملها بدون هزینههای مقیاس مرزی نیاز دارید، MiniMax-M2 به نقطه مطلوب میرسد: سرعت استنتاج سریع، قابلیتهای قوی استفاده از ابزار و ردپایی مناسب برای استقرار.
نحوه استفاده
- محصول MiniMax Agent ، که بر روی MiniMax-M2 ساخته شده است، اکنون به صورت عمومی در دسترس است و برای مدت محدودی رایگان است: https://agent.minimax.io
- API MiniMax-M2 اکنون در پلتفرم باز MiniMax فعال است و برای مدت محدودی رایگان است: https://platform.minimax.io/docs/guides/text-generation
- وزنهای مدل MiniMax-M2 اکنون متنباز هستند و امکان استقرار و استفاده محلی را فراهم میکنند: https://huggingface.co/MiniMaxAI/MiniMax-M2.
راهنمای استقرار محلی
مدل را از مخزن HuggingFace دانلود کنید: https://huggingface.co/MiniMaxAI/MiniMax-M2. با استفاده از چارچوبهای استنتاج زیر (به ترتیب حروف الفبا) را برای ارائه مدل توصیه میشود:
SGLang
استفاده از SGLang را برای ارائه MiniMax-M2 توصیه میشود. SGLang پشتیبانی روز صفر (day-0) محکمی را برای مدل MiniMax-M2 ارائه میدهد. لطفاً برای جزئیات بیشتر به راهنمای استقرار SGLang مراجعه کنید .
vLLM
استفاده از vLLM را برای ارائه MiniMax-M2 توصیه میشود زیرا vLLM پشتیبانی روز صفر کارآمدی را برای مدل MiniMax-M2 ارائه میدهد، برای آخرین راهنمای استقرار به https://docs.vllm.ai/projects/recipes/en/latest/MiniMax/MiniMax-M2.html میتوانید مراجعه کنید.
MLX
استفاده از MLX-LM را برای ارائه MiniMax-M2 نیز توصیه میشود. برای جزئیات بیشتر، لطفاً به راهنمای استقرار MLX در سایت مدل مراجعه کنید.
Transformers
استفاده از Transformers را برای سرویسدهی به MiniMax-M2 توصیه میشود. لطفاً برای جزئیات بیشتر به راهنمای استقرار Transformers سایت مرجع مراجعه کنید.
پارامترهای استنتاج
برای بهترین عملکرد، استفاده از این مفادیر برای پارامترها توصیه میشود:
temperature=1.0, top_p = 0.95, top_k = 40.
مهم: MiniMax-M2 یک مدل تفکر بین لایهای است. بنابراین، هنگام استفاده از آن، حفظ محتوای تفکر از نوبتهای دستیار در پیامهای تاریخچه مهم است. در محتوای خروجی مدل، از قالب <think>…</think> برای بستهبندی محتوای تفکر دستیار استفاده میشود. هنگام استفاده از مدل، باید مطمئن شوید که محتوای تاریخچه در قالب اصلی خود بازگردانده میشود. قسمت <think>…</think> را حذف نکنید، در غیر این صورت، عملکرد مدل تحت تأثیر منفی قرار خواهد گرفت.
راهنمای فراخوانی ابزار
لطفاً به راهنمای فراخوانی ابزار مراجعه کنید.
https://huggingface.co/MiniMaxAI/MiniMax-M2/blob/main/docs/tool_calling_guide.md