وقتی در حال توسعه یک مدل زبانی بزرگ (LLM) هستید، ارزیابی مدل فقط یک بار انجام نمیشود. تقریباً بعد از هر تغییر مهم باید دوباره سراغ ارزیابی بروید. هر تغییری در دادههای آموزشی، معماری مدل یا تنظیمات آموزش و حتی هر بار که اندازه و مقیاس مدل را افزایش میدهید، شما را وارد یک چرخه تکراری میکند:
ابتدا باید بنچمارکها را اضافه یا بهروزرسانی کنید، سپس آنها را روی نسخه جدید مدل اجرا کنید، نتایج را بررسی کنید و در نهایت ببینید آیا تغییری که در یک آزمایش کوچک نتیجه مثبتی داشته، در آموزش کامل مدل نیز همان تأثیر را حفظ کرده است یا خیر.
مشکل اینجاست که بیشتر ابزارهای ارزیابی موجود برای چنین فرآیندی ساخته نشدهاند. این ابزارها معمولاً برای یکی از دو هدف طراحی شدهاند: یا اجرای مجموعهای از بنچمارکهای استاندارد روی مدلهای نهایی، یا آزمایش مدل در محیطهای شبیهسازیشده و کنترلشده که در آن باید مسائل چندمرحلهای را با استفاده از ابزارهای مختلف حل کند.
اما توسعه واقعی یک مدل زبانی با این سناریوها تفاوت دارد. مدل در طول مسیر دائماً تغییر میکند و نسخههای جدیدی از آن ساخته میشود. بسیاری از ابزارهای فعلی نمیتوانند خود را با این تغییرات مداوم هماهنگ کنند و از طرف دیگر، تصویر دقیقی از رفتار مدل در شرایط واقعی ارائه نمیدهند.
برای حل این مشکل، ما پیشتر پروژهای به نام OLMES (استاندارد باز ارزیابی مدلهای زبانی) را معرفی کرده بودیم. این پروژه که در سال ۲۰۲۴ منتشر شد، با هدف استانداردسازی فرآیند ارزیابی مدلهای زبانی ایجاد شد تا نتایج بنچمارکها در نسخههای مختلف قابل مقایسه باشند.
در آن زمان یک مشکل رایج وجود داشت: پژوهشگران مختلف یک مدل را روی یک بنچمارک مشترک ارزیابی میکردند، اما هر کدام از قالببندی پرامپتها، روش تعریف وظایف یا تنظیمات متفاوتی استفاده میکردند. در نتیجه، حتی وقتی مدل و بنچمارک یکسان بودند، نتایج بهدستآمده تفاوت داشت و مقایسه آنها چندان قابل اعتماد نبود.
OLMES تلاش کرد این مشکل را با تعریف یک استاندارد شفاف و مستند برطرف کند. این استاندارد بعدها به مبنای اصلی ارزیابی مدلهای متنباز AI2 از جمله OLMo و Tulu تبدیل شد.
با این حال، امتیاز نهایی یک مدل تنها بخش کوچکی از فرآیند ارزیابی است. توسعهدهندگان در طول ساخت مدل به اطلاعات بسیار بیشتری نیاز دارند. به همین دلیل OLMo-Eval معرفی شده است.
OLMo-Eval بر پایه OLMES ساخته شده، اما دامنه فعالیت آن بسیار گستردهتر است. این ابزار فقط برای اندازهگیری نتیجه نهایی مدل طراحی نشده، بلکه کل چرخه توسعه مدل را پوشش میدهد.
در مقایسه با OLMES، این سیستم فرآیند ایجاد ارزیابیهای جدید را سادهتر میکند، انعطاف بیشتری در نحوه و محل اجرای آزمونها در اختیار توسعهدهندگان قرار میدهد و امکان ترکیب اجزای مختلف در پروژههای بزرگتر را فراهم میکند.
یکی دیگر از ویژگیهای مهم OLMo-Eval پشتیبانی کامل از ارزیابی Agentها و سناریوهای چندمرحلهای است؛ موضوعی که امروز به یکی از مهمترین روندهای صنعت هوش مصنوعی تبدیل شده است. همچنین ابزارهای تحلیلی پیشرفتهتری در اختیار پژوهشگران قرار میدهد تا بتوانند تشخیص دهند آیا تغییری که روی مدل اعمال کردهاند واقعاً باعث بهبود عملکرد شده است یا اختلاف مشاهدهشده فقط در حد نوسانات آماری و نویز است.
به بیان ساده، OLMo-Eval میخواهد ارزیابی را از یک مرحله پایانی در پروژه به بخشی دائمی از فرآیند توسعه مدل تبدیل کند؛ جایی که پژوهشگران بتوانند در هر مرحله از ساخت مدل، با دقت بیشتری پیشرفت واقعی آن را اندازهگیری و تحلیل کنند.
OLMo-Eval چه تفاوتی با ابزارهای فعلی دارد؟
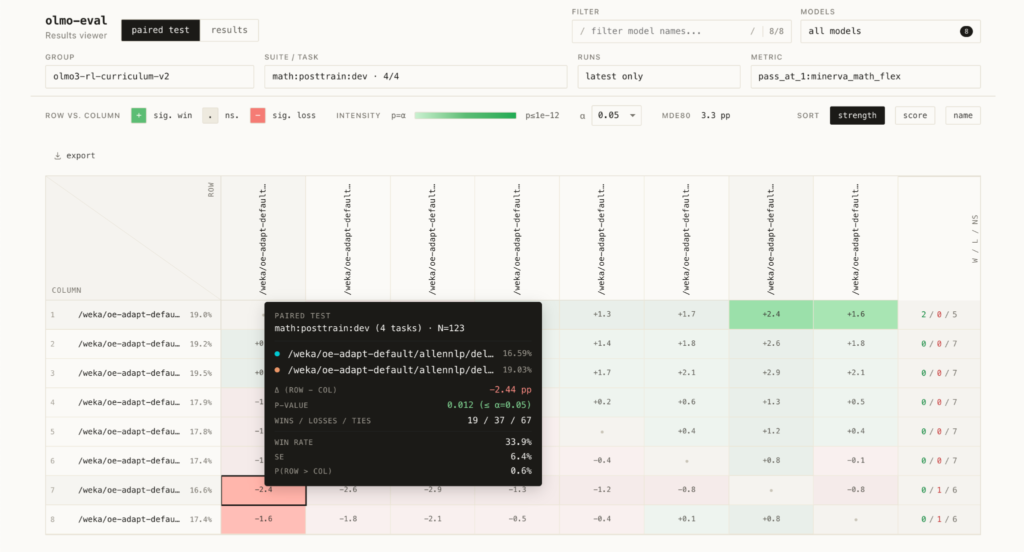
آیا افزایش ۲.۴ درصدی واقعاً به معنی بهتر شدن مدل است؟
OLMo-Eval در برخی زمینهها شباهتهایی با Harbor دارد؛ Harbor یک چارچوب متنباز برای ارزیابی عاملهای هوش مصنوعی در محیطهای ایزوله و مبتنی بر کانتینر است. با این حال، فلسفه طراحی و کاربرد این دو ابزار کاملاً متفاوت است.
Harbor بیشتر برای اجرای بنچمارکها و انتشار نتایج ارزیابی Agentها ساخته شده است. در مقابل، OLMo-Eval برای نیازهای روزمره تیمهای توسعه مدل طراحی شده؛ یعنی جایی که مهندسان دائماً در حال اضافه کردن بنچمارکهای جدید، آزمایش نسخههای مختلف مدل و بررسی تأثیر تغییرات روی عملکرد آن هستند.
به جای اینکه فقط یک نمره کلی از مدل دریافت کنید، OLMo-Eval به شما اجازه میدهد نتایج را در سطح تکتک پرسشها بررسی کنید و دقیقاً ببینید چه چیزی تغییر کرده است.
اجرای ارزیابی به اندازه نیاز
در Harbor همه ارزیابیها داخل کانتینرهای کاملاً ایزوله اجرا میشوند تا نتایج همیشه قابل تکرار باشند. این روش مزایای زیادی دارد، اما هزینه پردازشی و مصرف منابع آن نیز بالاست.
OLMo-Eval رویکرد متفاوتی را انتخاب کرده است.
اگر یک بنچمارک تنها به پاسخگویی مدل نیاز داشته باشد، ارزیابی مستقیماً اجرا میشود؛ روشی که هم سریعتر است و هم هزینه کمتری دارد.
اما اگر ارزیابی به محیطی کنترلشده نیاز داشته باشد، مثلاً قرار باشد مدلی که کد تولید کرده آن را اجرا کند، سیستم بهطور خودکار از محیط ایزوله استفاده میکند.
به بیان ساده، OLMo-Eval تنها زمانی سراغ زیرساختهای سنگین میرود که واقعاً لازم باشد.
اضافه کردن بنچمارک بدون دردسر
فرآیند اضافه کردن یک بنچمارک در Harbor بیشتر مناسب پروژههایی است که قرار است نتایج آنها بهصورت عمومی منتشر شود. به همین دلیل مراحل کنترل کیفیت و اعتبارسنجی بیشتری در آن وجود دارد.
اما OLMo-Eval برای سرعت بخشیدن به فرآیند توسعه ساخته شده است.
اگر یک ارزیابی ساده باشد، با چند خط تعریف قابل اضافه شدن است. اگر ارزیابی پیچیدهتر باشد و از قبل کد اختصاصی خودش را داشته باشد، کافی است یک لایه ارتباطی ساده به آن اضافه شود تا بتواند در چارچوب OLMo-Eval اجرا شود و نتایج آن در کنار سایر ارزیابیها ثبت گردد.
همه چیز قابل تعویض است
یکی از جذابترین ویژگیهای OLMo-Eval معماری ماژولار آن است.
در این سیستم تقریباً هیچ بخشی ثابت و غیرقابل تغییر نیست.
مدلی که در حال ارزیابی است، ابزارهایی که استفاده میکند، محیط اجرایی، مدلهای کمکی و حتی مدل داور همگی میتوانند بدون ایجاد اختلال در سایر بخشها جایگزین شوند.
برای مثال، میتوانید امروز از یک مدل بهعنوان داور استفاده کنید و فردا آن را با مدل دیگری جایگزین کنید، بدون اینکه نیاز به تغییر کل فرآیند ارزیابی داشته باشید.
همین موضوع در مورد ابزارها و تنظیمات مختلف نیز صدق میکند.
فراتر از یک عدد
بیشتر ابزارهای ارزیابی در نهایت یک عدد به شما تحویل میدهند.
مثلاً:
نسخه اول مدل: ۸۲ امتیاز
نسخه دوم مدل: ۸۴ امتیاز
اما سؤال مهم اینجاست:
این دو امتیاز دقیقاً چه چیزی را نشان میدهند؟
آیا مدل واقعاً بهتر شده است یا فقط تفاوت مشاهدهشده در محدوده خطای آماری قرار دارد؟
OLMo-Eval علاوه بر امتیاز نهایی، اطلاعات آماری مهمی را نیز ارائه میکند تا بتوان میزان اطمینان به نتایج را سنجید.
اما مهمتر از آن، امکان مقایسه مستقیم دو نسخه از مدل را در سطح سؤال به سؤال فراهم میکند.
به این ترتیب میتوانید ببینید:
- کدام سؤالها در نسخه جدید بهتر پاسخ داده شدهاند.
- کدام بخشها افت عملکرد داشتهاند.
- و دقیقاً چه تغییری باعث جابهجایی نمره کلی شده است.
چرا این موضوع مهم است؟
در توسعه مدلهای زبانی، افزایش چند دهم درصدی عملکرد همیشه به معنی پیشرفت واقعی نیست. گاهی اوقات تفاوتی که روی نمودار دیده میشود صرفاً ناشی از نویز آماری است.
OLMo-Eval تلاش میکند این ابهام را از بین ببرد و به تیمهای توسعه کمک کند با اطمینان بیشتری تصمیم بگیرند که آیا یک تغییر واقعاً ارزش نگهداشتن دارد یا خیر.
در واقع، این ابزار به جای اینکه فقط بگوید «مدل بهتر شده است»، تلاش میکند توضیح دهد «چرا بهتر شده» و «این بهبود تا چه حد واقعی است».
یک پشته یکپارچه برای ارزیابی مدلهای زبانی
OLMo-Eval از چهار بخش اصلی تشکیل شده است. هر کدام از این بخشها بهتنهایی کاربرد دارند، اما بهگونهای طراحی شدهاند که در کنار یکدیگر کار کنند و فرآیند آزمایش، ارزیابی و بهبود مدلهای زبانی را سریعتر، دقیقتر و قابلمدیریتتر کنند.
۱. جداسازی «بنچمارک» از «نحوه اجرا»
اولین بخش OLMo-Eval بر پایه سه مفهوم اصلی بنا شده است:
- Task (وظیفه)
- Suite (مجموعه)
- Harness (محیط یا روش اجرا)
در این ساختار، منطق بنچمارک از نحوه اجرای آن جدا میشود.
Task مشخص میکند چه چیزی قرار است ارزیابی شود. در واقع خود بنچمارک در این قسمت تعریف میشود.
Suite مجموعهای از چند Task است که میتوان آنها را بهصورت همزمان اجرا کرد.
Harness تعیین میکند هر Task چگونه اجرا شود؛ مثلاً مدل از چه ابزارهایی استفاده کند، در چه محیطی اجرا شود یا چه Agentی آن را هدایت کند.
مزیت این جداسازی آن است که میتوان یک بنچمارک ثابت را با روشهای مختلف اجرا کرد، بدون آنکه ماهیت ارزیابی تغییر کند.
برای مثال، یک آزمون میتواند:
- یک بار بهصورت ساده و بدون ابزار اجرا شود.
- بار دیگر با دسترسی به جستجوی وب اجرا شود.
- بار سوم با یک Agent چندمرحلهای اجرا شود.
در هر سه حالت، معیار ارزیابی یکسان باقی میماند و تنها نحوه اجرای مدل تغییر میکند.
۲. لایه Sandbox و مدیریت قابلیتها
بخش دوم مربوط به سیستم Sandbox و مدیریت ابزارها است.
بسیاری از مدلهای جدید فقط پاسخ متنی تولید نمیکنند. آنها ممکن است:
- کد بنویسند
- کد را اجرا کنند
- در وب جستجو کنند
- فایلها را تحلیل کنند
- با ابزارهای مختلف تعامل داشته باشند
در چنین شرایطی نمیتوان صرفاً خروجی متنی مدل را ارزیابی کرد.
باید بررسی شود مدل هنگام استفاده از ابزارها در عمل چگونه رفتار میکند.
برای حل این مسئله، OLMo-Eval دارای یک لایه Sandbox است که ابزارهای موردنیاز را اجرا میکند و نتایج آنها را دوباره به مدل بازمیگرداند.
به عنوان مثال:
مدل درخواست میکند:
کد پایتون را اجرا کن.
سیستم Sandbox کد را اجرا میکند.
نتیجه اجرا به مدل بازگردانده میشود.
سپس مدل بر اساس آن نتیجه پاسخ نهایی خود را تولید میکند.
در نتیجه ارزیابی فقط بر پایه توانایی تولید متن نیست، بلکه توانایی واقعی مدل در استفاده از ابزارها نیز سنجیده میشود.
۳. ثبت استاندارد همه آزمایشها
سومین بخش، سیستم ثبت و ذخیرهسازی نتایج است.
در پروژههای بزرگ هوش مصنوعی ممکن است صدها یا حتی هزاران آزمایش مختلف انجام شود.
برای مثال:
- نسخههای مختلف مدل
- دادههای آموزشی متفاوت
- تنظیمات آموزشی گوناگون
- بنچمارکهای مختلف
اگر نتایج به شکل استاندارد ذخیره نشوند، مقایسه آنها بسیار دشوار خواهد شد.
OLMo-Eval برای حل این مشکل از یک ساختار استاندارد استفاده میکند که در آن:
- مشخصات هر آزمایش
- تنظیمات مورد استفاده
- نسخه مدل
- بنچمارکها
- نتایج نهایی
همگی در قالبی یکسان ذخیره میشوند.
این کار چند مزیت مهم دارد:
- مقایسه آسان Checkpointهای مختلف
- بررسی روند پیشرفت مدل در طول زمان
- مدیریت سادهتر پروژههای بلندمدت
- جلوگیری از خطاها و ناهماهنگیهایی که معمولاً در پروژههای بزرگ ایجاد میشوند
۴. ابزار مقایسه دقیق نتایج
چهارمین بخش، نمایشگر مقایسه نتایج است.
در بسیاری از سیستمهای ارزیابی تنها یک عدد نهایی نمایش داده میشود.
مثلاً:
| مدل | امتیاز |
|---|---|
| نسخه A | 82.4 |
| نسخه B | 84.1 |
اما این اعداد همیشه تصویر کاملی ارائه نمیکنند.
ممکن است مدل جدید در برخی حوزهها بهتر شده باشد و در برخی دیگر ضعیفتر.
OLMo-Eval امکان مقایسه دو مدل یا دو Checkpoint را در سطح تکتک پرسشها فراهم میکند.
یعنی میتوان مشاهده کرد:
- کدام سؤالها بهبود یافتهاند.
- کدام پاسخها افت کردهاند.
- چه بخشهایی بدون تغییر ماندهاند.
این رویکرد باعث میشود تغییرات کوچکی که در میانگین کلی پنهان میشوند، بهوضوح دیده شوند.
در نتیجه پژوهشگران بهتر میتوانند تشخیص دهند که آیا یک تغییر واقعاً باعث پیشرفت مدل شده یا خیر.
در بیشتر سیستمهای ارزیابی مدلها، اضافه کردن یک بنچمارک (معیار سنجش) یک پروژه یکپارچهسازی بزرگ و زمانبر محسوب میشود. اما در olmo-eval تنها چیزی که نیاز دارید یک «تسک» است—تسکها مشخص میکنند دیتاست بنچمارک چیست، درخواستهای ارزیابی چگونه ساخته میشوند و پاسخهای مدل چگونه امتیازدهی میشوند (همه این موارد با کد پایتون پیادهسازی میشوند).
from olmo_eval.common.formatters import ChatFormatter from olmo_eval.common.metrics import AccuracyMetric from olmo_eval.common.scorers import ExactMatchScorer from olmo_eval.common.types import Instance, SamplingParams from olmo_eval.data import DataLoader, DataSource from olmo_eval.evals.tasks.common import Task, register, register_variant @register("internal_freshqa") class InternalFreshQA(Task): data_source = DataSource(path="s3://evals/internal/freshqa.jsonl", split="test") formatter = ChatFormatter() sampling_params = SamplingParams(temperature=0.0) metrics = (AccuracyMetric(scorer=ExactMatchScorer),) @property def instances(self): loader = DataLoader() for idx, doc in enumerate(loader.load(self.config.get_data_source())): yield Instance( question=doc["question"], gold_answer=doc["answer"], metadata={"id": doc.get("id", f"freshqa_{idx}")}, )
«واریانتها (Variants) تغییرات در سیاست ارزیابی را بدون نیاز به تکرار یا کپی کردن خود بنچمارک بیان میکنند.»
register_variant("internal_freshqa", "3shot", num_fewshot=3, fewshot_seed=1234)
register_variant("internal_freshqa", "zero", num_fewshot=0)
«سویتها (Suites) بنچمارکها را در قالب مجموعههای استاندارد گروهبندی میکنند که بهصورت یکجا اجرا میشوند.»
from olmo_eval.evals.suites import Suite, register
register(Suite(
name="base_qa_few_shot",
tasks=(
"sciq:mc:3shot",
"arc_challenge:mc:3shot",
"internal_freshqa:mc:3shot",
),
))
و از آنجا که منطق اجرای مدل (runtime policy) در «هارنس» قرار دارد، نه در تعریف تسک، میتوان یک بنچمارک واحد را بهسادگی تحت شرایط اجرایی متفاوت دوباره اجرا کرد، بدون اینکه نتایج صرفاً بر این اساس ارزیابی شوند که آیا یک مسیر تولیدشده در نگاه اول قابلقبول به نظر میرسد یا نه.
# Baseline
olmo-eval run -m my-instruct-checkpoint -t internal_freshqa:zero
# Same task, same scoring, search/tool runtime enabled
olmo-eval run -m my-instruct-checkpoint -t internal_freshqa:zero --harness search_agent
منبع : https://huggingface.co/blog/allenai/olmo-eval