Vox CPM یک سیستم تبدیل متن به صوت انگلیسی (TTS) جدید بدون نیاز به توکنساز است. مدلی که واقعگرایی در ترکیب گفتار را از نو تعریف میکند. این سیستم با مدلسازی گفتار در یک فضای پیوسته، بر محدودیتهای توکنسازی گسسته غلبه میکند. هم چنین دو قابلیت شاخص را فعال میکند: تولید گفتار آگاه از متن و شبیهسازی صدای zero-shot واقعی.
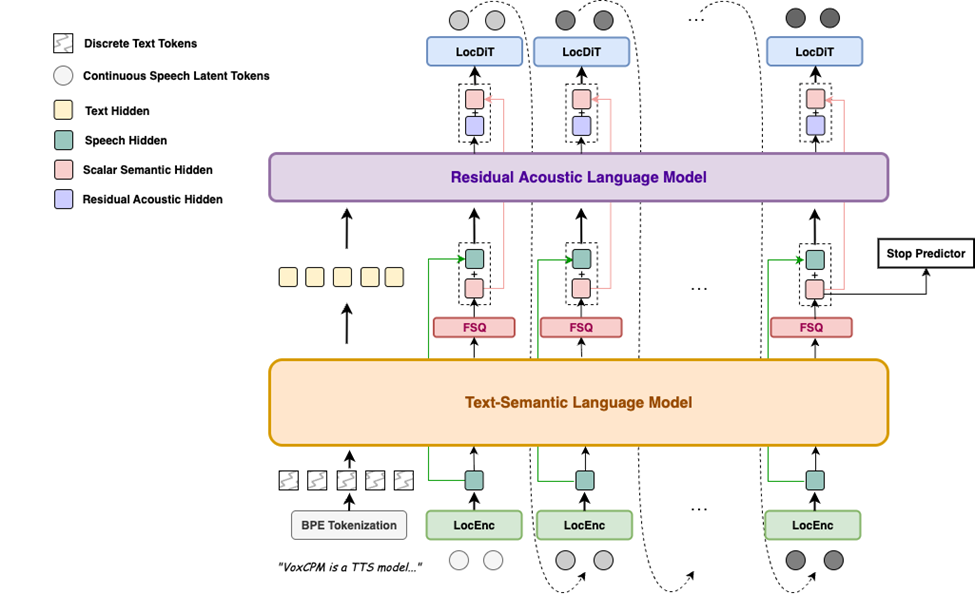
برخلاف رویکردهای رایج که گفتار را به توکنهای گسسته تبدیل میکنند، Vox CPM از یک معماری خودرگرسیو انتشار انتها به انتها استفاده میکند که مستقیماً بازنماییهای گفتار پیوسته را از متن تولید میکند. این سیستم که بر پایه MiniCPM-4 ساخته شده است، از طریق مدلسازی سلسله مراتبی زبان و محدودیتهای FSQ به جداسازی ضمنی معنایی-صوتی دست مییابد. این بدین معناست که هم بیان و هم پایداری تولید را تا حد زیادی افزایش میدهد.
🚀 ویژگیهای کلیدی
تولید گفتار رسا و آگاه از متن – Vox CPM متن را درک میکند تا نوای مناسب را استنباط و تولید کند و گفتار را با رسایی قابل توجه و گفتار طبیعی ارائه دهد. این نرمافزار به طور خودجوش سبک گفتار را بر اساس محتوا تطبیق میدهد و بیان صوتی بسیار متناسبی با توجه به آموزش بر روی یک مجموعه عظیم ۱.۸ میلیون ساعته دوزبانه ، تولید میکند.
شبیهسازی صدای واقعی – Vox CPM تنها با یک کلیپ صوتی مرجع کوتاه، شبیهسازی صدای دقیق و بدون نقص را انجام میدهد و نه تنها طنین صدای گوینده، بلکه ویژگیهای جزئی مانند لهجه، لحن احساسی، ریتم و سرعت را نیز ضبط میکند تا یک کپی دقیق و طبیعی ایجاد کند.
سنتز با راندمان بالا – Vox CPM از سنتز جریانی با ضریب زمان واقعی (RTF) تا ۰.۱۷ در یک پردازنده گرافیکی NVIDIA RTX 4090 در سطح مصرفکننده پشتیبانی میکند و این امر را برای برنامههای زمان واقعی امکانپذیر میسازد.
راه اندازی و استفاده سریع
🔧 نصب از PyPI
pip install voxcpmدانلود مدل (اختیاری)
به طور پیشفرض، وقتی برای اولین بار اسکریپت را اجرا میکنید، مدل به طور خودکار دانلود میشود، اما میتوانید مدل را از قبل نیز دانلود کنید.
دانلود VoxCPM-0.5B
from huggingface_hub import snapshot_download
snapshot_download("openbmb/VoxCPM-0.5B")دانلود ZipEnhancer و SenseVoice-Small:
ما در نسخه آزمایشی وب از ZipEnhancer برای بهبود اعلانهای گفتاری و از SenseVoice-Small برای ASR(Automatic Speech Recognition یا تشخیص خودکار صوت) اعلان گفتاری استفاده میکنیم.
from modelscope import snapshot_download
from modelscope import snapshot_download
snapshot_download('iic/speech_zipenhancer_ans_multiloss_16k_base')
snapshot_download('iic/SenseVoiceSmall')کاربرد اولیه
import soundfile as sf
import numpy as np
from voxcpm import VoxCPM
model = VoxCPM.from_pretrained("openbmb/VoxCPM-0.5B")
# Non-streaming
wav = model.generate(
text="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech.",
prompt_wav_path=None, # optional: path to a prompt speech for voice cloning
prompt_text=None, # optional: reference text
cfg_value=2.0, # LM guidance on LocDiT, higher for better adherence to the prompt, but maybe worse
inference_timesteps=10, # LocDiT inference timesteps, higher for better result, lower for fast speed
normalize=True, # enable external TN tool
denoise=True, # enable external Denoise tool
retry_badcase=True, # enable retrying mode for some bad cases (unstoppable)
retry_badcase_max_times=3, # maximum retrying times
retry_badcase_ratio_threshold=6.0, # maximum length restriction for bad case detection (simple but effective), it could be adjusted for slow pace speech
)
sf.write("output.wav", wav, 16000)
print("saved: output.wav")
# Streaming
chunks = []
for chunk in model.generate_streaming(
text = "Streaming text to speech is easy with VoxCPM!",
# supports same args as above
):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("output_streaming.wav", wav, 16000)
print("saved: output_streaming.wav")
کاربرد رابط خط فرمان (CLI)
پس از نصب، برای استفاده در ترمینال دستور ورود voxcpm است (یا از python -m voxcpm.cli استفاده کنید).
# 1) Direct synthesis (single text)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." --output out.wav
# 2) Voice cloning (reference audio + transcript)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--output out.wav \
--denoise
# (Optinal) Voice cloning (reference audio + transcript file)
voxcpm --text "VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly expressive speech." \
--prompt-audio path/to/voice.wav \
--prompt-file "/path/to/text-file" \
--output out.wav \
--denoise
# 3) Batch processing (one text per line)
voxcpm --input examples/input.txt --output-dir outs
# (optional) Batch + cloning
voxcpm --input examples/input.txt --output-dir outs \
--prompt-audio path/to/voice.wav \
--prompt-text "reference transcript" \
--denoise
# 4) Inference parameters (quality/speed)
voxcpm --text "..." --output out.wav \
--cfg-value 2.0 --inference-timesteps 10 --normalize
# 5) Model loading
# Prefer local path
voxcpm --text "..." --output out.wav --model-path /path/to/VoxCPM_model_dir
# Or from Hugging Face (auto download/cache)
voxcpm --text "..." --output out.wav \
--hf-model-id openbmb/VoxCPM-0.5B --cache-dir ~/.cache/huggingface --local-files-only
# 6) Denoiser control
voxcpm --text "..." --output out.wav \
--no-denoiser --zipenhancer-path iic/speech_zipenhancer_ans_multiloss_16k_base
# 7) Help
voxcpm --help
python -m voxcpm.cli –help
استفاده از نسخه آزمایشی وب
شما میتوانید رابط کاربری را با اجرای python app.py شروع کنید، که به شما امکان میدهد شبیهسازی صدا و ایجاد صدا را انجام دهید. برای این کار ابتدا باید پروژه را از گیت هاب دریافت نمایید سپس دستور زیر را با رفتن به پوشه پروژه در ترمینال اجرا نمایید
⚠️ خطرات و محدودیتها
رفتار کلی مدل: اگرچه آموزش دیدن مدل بر روی مجموعه اطلاعاتی در مقیاس بزرگ است، اما همچنان ممکن است خروجیهایی تولید کند که غیرمنتظره، جانبدارانه یا حاوی مصنوعات باشند.
پتانسیل سوءاستفاده از شبیهسازی صدا: قابلیت قدرتمند شبیهسازی صدای zero-shot میتواند گفتار مصنوعی بسیار واقعگرایانهای تولید کند. این فناوری میتواند برای ایجاد دیپفیکهای قانعکننده به منظور جعل هویت، کلاهبرداری یا انتشار اطلاعات نادرست مورد سوءاستفاده قرار گیرد. کاربران این مدل نباید از آن برای ایجاد محتوایی که حقوق افراد را نقض میکند، استفاده کنند. استفاده از این مدل برای هرگونه هدف غیرقانونی یا غیراخلاقی اکیداً ممنوع است. اکیداً توصیه میشود که هرگونه محتوای تولیدی عمومی با این مدل، به وضوح به عنوان تولید توسط هوش مصنوعی مشخص شود.
محدودیتهای فنی فعلی: اگرچه به طور کلی پایدار است، اما ممکن است گاهی اوقات، به ویژه با ورودیهای بسیار طولانی یا رسا، ناپایداری نشان دهد. علاوه بر این موضوع، نسخه فعلی کنترل مستقیم محدودی بر ویژگیهای خاص گفتار مانند احساسات یا سبک صحبت ارائه میدهد.
مدل دوزبانه: آموزش مدل در درجه اول بر روی دادههای چینی و انگلیسی است بنابراین عملکرد در زبانهای دیگر تضمین نمیشود و ممکن است منجر به صدای غیرقابل پیشبینی یا کمکیفیت شود.
این مدل فقط برای اهداف تحقیق و توسعه است. استفاده از آن را در برنامههای تولیدی یا تجاری بدون آزمایش دقیق و ارزیابیهای ایمنی توصیه نمیشود.