
مدل متفکر کیمی کی۲ (Kimi-K2-Thinking) جدیدترین و توانمندترین نسخه از مدل تفکر متنباز است. کیمی کی۲ به عنوان یک عامل تفکر ساخته شده است که گام به گام استدلال میکند و در عین حال به صورت پویا ابزارها را فراخوانی میکند. این مدل با افزایش چشمگیر عمق استدلال چند مرحلهای و حفظ پایداری استفاده از ابزار در طول ۲۰۰ تا ۳۰۰ فراخوانی متوالی، یک پیشرفت جدید در آزمونهای آخرین امتحان بشریت(HLE)، مرورکامپ (BrowseComp) و سایر معیارها ایجاد میکند. در عین حال،مدل متفکر کی۲ یک مدل کوانتیزاسیون بومی INT4 با پنجره متن ۲۵۶ کیلوبایتی است که به کاهش بدون اتلاف در تأخیر استنتاج و استفاده از حافظه GPU دست مییابد.
ویژگیهای کلیدی
- تفکر عمیق و هماهنگسازی ابزار: مدل آموزش دیده تا از ابتدا تا انتها برای درهم آمیختن استدلال زنجیرهای از افکار با فراخوانیهای تابع، امکان تحقیق، کدنویسی و نوشتن گردشهای کاری مستقل را فراهم کند که صدها مرحله بدون drift به طول میانجامد.
- کوانتیزاسیون بومی INT4: آموزش آگاه از کوانتیزاسیون (QAT) در مرحله پس از آموزش برای دستیابی به سرعت دو برابر بدون اتلاف در حالت تأخیر کم به کار گرفته میشود.
- عملکرد پایدار بلندمدت: رفتار منسجم و هدفمند را در طول حداکثر ۲۰۰ تا ۳۰۰ فراخوانی متوالی ابزار حفظ میکند و از مدلهای قبلی که پس از ۳۰ تا ۵۰ مرحله دچار افت کیفیت میشوند، پیشی میگیرد.
خلاصه مدل
| معماری | Mixture-of-Experts (MoE) |
| تعداد کل پارامترها | 1T |
| تعداد پارامترهای فعال | 32B |
| تعداد کل لایه ها | 61 |
| تعداد لایه های میانی | 1 |
| ابعاد توجه پنهان | 7168 |
| ابعاد متخصصین پنهان | 2048 |
| تعداد توجه های موازی | 64 |
| تعداد متخصصین | 384 |
| متخصصین انتخاب شده بر توکن | 8 |
| تعداد متخصصین اشتراکی | 1 |
| اندازه | 160K |
| طول متن | 256K |
| ساز و کار توجه | MLA |
| تابع فعالساز | SwiGLU |
نتایج ارزیابی
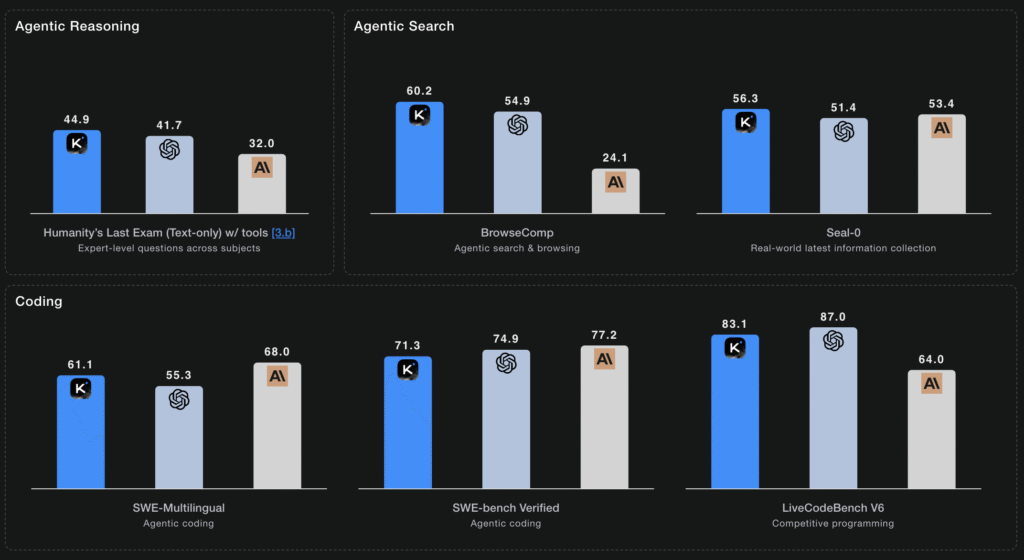
وظایف استدلال(reasoning task)
| معیار | تنظیمات | K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | K2 0905 | DeepSeek-V3.2 | Grok-4 |
|---|---|---|---|---|---|---|---|
| HLE (Text-only) | no tools | 23.9 | 26.3 | 19.8* | 7.9 | 19.8 | 25.4 |
| w/ tools | 44.9 | 41.7* | 32.0* | 21.7 | 20.3* | 41.0 | |
| heavy | 51.0 | 42.0 | – | – | – | 50.7 | |
| AIME25 | no tools | 94.5 | 94.6 | 87.0 | 51.0 | 89.3 | 91.7 |
| w/ python | 99.1 | 99.6 | 100.0 | 75.2 | 58.1* | 98.8 | |
| heavy | 100.0 | 100.0 | – | – | – | 100.0 | |
| HMMT25 | no tools | 89.4 | 93.3 | 74.6* | 38.8 | 83.6 | 90.0 |
| w/ python | 95.1 | 96.7 | 88.8* | 70.4 | 49.5* | 93.9 | |
| heavy | 97.5 | 100.0 | – | – | – | 96.7 | |
| IMO-AnswerBench | no tools | 78.6 | 76.0* | 65.9* | 45.8 | 76.0* | 73.1 |
| GPQA | no tools | 84.5 | 85.7 | 83.4 | 74.2 | 79.9 | 87.5 |
وظایف عمومی
| معیار | تنظیمات | K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|
| MMLU-Pro | no tools | 84.6 | 87.1 | 87.5 | 81.9 | 85.0 |
| MMLU-Redux | no tools | 94.4 | 95.3 | 95.6 | 92.7 | 93.7 |
| Longform Writing | no tools | 73.8 | 71.4 | 79.8 | 62.8 | 72.5 |
| HealthBench | no tools | 58.0 | 67.2 | 44.2 | 43.8 | 46.9 |
جستجوی عامل(agentic search)
| معیار | تنظیمات | K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|
| BrowseComp | w/ tools | 60.2 | 54.9 | 24.1 | 7.4 | 40.1 |
| BrowseComp-ZH | w/ tools | 62.3 | 63.0* | 42.4* | 22.2 | 47.9 |
| Seal-0 | w/ tools | 56.3 | 51.4* | 53.4* | 25.2 | 38.5* |
| FinSearchComp-T3 | w/ tools | 47.4 | 48.5* | 44.0* | 10.4 | 27.0* |
| Frames | w/ tools | 87.0 | 86.0* | 85.0* | 58.1 | 80.2* |
کد نویسی
| معیار | تنظیمات | K2 Thinking | GPT-5 (High) | Claude Sonnet 4.5 (Thinking) | K2 0905 | DeepSeek-V3.2 |
|---|---|---|---|---|---|---|
| SWE-bench Verified | w/ tools | 71.3 | 74.9 | 77.2 | 69.2 | 67.8 |
| SWE-bench Multilingual | w/ tools | 61.1 | 55.3* | 68.0 | 55.9 | 57.9 |
| Multi-SWE-bench | w/ tools | 41.9 | 39.3* | 44.3 | 33.5 | 30.6 |
| SciCode | no tools | 44.8 | 42.9 | 44.7 | 30.7 | 37.7 |
| LiveCodeBenchV6 | no tools | 83.1 | 87.0* | 64.0* | 56.1* | 74.1 |
| OJ-Bench (cpp) | no tools | 48.7 | 56.2* | 30.4* | 25.5* | 38.2* |
| Terminal-Bench | w/ simulated tools (JSON) | 47.1 | 43.8 | 51.0 | 44.5 | 37.7 |
توضیحات ارزیابی ها
برای اطمینان از یک تجربه سریع و سبک، به صورت انتخابی از زیرمجموعهای از ابزارها استفاده شدند و تعداد مراحل فراخوانی ابزار را در حالت چت در kimi.com کاهش دادند. در نتیجه، چت در kimi.com ممکن است نمرات معیار بالا را بازتولید نکند. حالت عامل به زودی بهروزرسانی خواهد شد تا قابلیتهای کامل K2 Thinking را منعکس کند.
جزئیات آزمایش:
- همه معیارها در دمای = ۱.۰ (temperature) و طول متن ۲۵۶ کیلوبایتی برای K2 Thinking ارزیابی شدند، به جز SciCode که برای آن از تنظیم دمای رسمی ۰.۰ پیروی گردیده است.
- HLE (بدون ابزار)، AIME25، HMMT25 و GPQA با بودجه توکن تفکر ۹۶ کیلوبایتی محدود شدند، در حالی که IMO-Answer Bench، LiveCodeBench و OJ-Bench با بودجه توکن تفکر ۱۲۸ کیلوبایتی محدود شدند. Longform Writing با بودجه توکن تکمیل ۳۲ کیلوبایتی محدود شد.
- برای AIME و HMMT (بدون ابزار)، میانگین ۳۲ اجرا (avg@32)، برای AIME و HMMT (با پایتون)، میانگین ۱۶ اجرا (avg@16) و برای IMO-AnswerBench، میانگین ۸ اجرا (avg@8) را گزارش گردید.
مبانی:
- نتایج GPT-5، Claude-4.5-sonnet، Grok-4 و نتایج DeepSeek-V3.2 ، جدول امتیازات عمومی Terminal-Bench (Terminus-2)، جدول امتیازات عمومی Vals AI و تحلیل مصنوعی نقل قول شدهاند. معیارهایی که هیچ امتیاز عمومی در دسترس برای آنها تحت همان شرایط مورد استفاده برای مدل تفکر k2 نبود، دوباره آزمایش نشده و با ستاره (*) مشخص شدهاند. برای آزمون GPT-5، تلاش استدلال بر روی میزان بالا تنظیم شد.
- نمرات GPT-5 و Grok-4 در مجموعه کامل HLE با ابزارها، از پستهای رسمی، ۳۵.۲ و ۳۸.۶ است. در ارزیابی داخلی و در زیرمجموعه فقط متنی HLE، GPT-5 امتیاز ۴۱.۷ و Grok-4 امتیاز ۳۸.۶ را کسب کرد (در زمان عرضه Grok-4، امتیاز ۴۱.۰ در زیرمجموعه فقط متنی گزارش شد). برای ابزار فقط متنی HLE GPT-5 بدون ابزار، از امتیاز Scale.ai استفاده گردیده است. مجموعه کامل رسمی GPT5 HLE بدون ابزار، ۲۴.۸ است.
- برای IMO-AnswerBench: GPT-5 در مقاله معیار، امتیاز ۶۵.۶ را کسب کرد. GPT-5 با API رسمی دوباره ارزیابی شد و امتیاز 76 را کسب کرد.
معیارهای HLE (با ابزارها) و جستجوی عامل:
- K2 Thinking به ابزارهای جستجو، مفسر کد و مرور وب مجهز بود.
- BrowseComp-ZH، Seal-0 و FinSearchComp-T3 چهار بار به طور مستقل اجرا شدند و میانگین آنها گزارش گردید (avg@4).
- در ارزیابی از o3-mini به عنوان داور استفاده شد که دقیقاً با تنظیمات رسمی HLE پیکربندی گردید؛ دستورات داوری کلمه به کلمه از مخزن رسمی گرفته شدند.
- در HLE، حداکثر محدودیت گام 120 ، با بودجه استدلال 48k-token در هر گام؛ در وظایف جستجوی عامل، محدودیت 300 گام با بودجه استدلال 24 k-token در هر گام در نظر گرفته شد.
- وقتی نتایج اجرای ابزار باعث میشود ورودی انباشتهشده از محدودیت زمینه مدل (۲۵۶ کیلوبایت) فراتر رود، از یک استراتژی مدیریت زمینه ساده استفاده میشود که تمام خروجیهای قبلی ابزار را پنهان میکند.
- دسترسی وب به Hugging Face ممکن است منجر به نشت دادهها در برخی از تستهای معیارها، مانند HLE، شود. K2 Thinking میتواند بدون مسدود کردن Hugging Face، امتیاز ۵۱.۳ را در HLE کسب کند. برای اطمینان از مقایسهای منصفانه و دقیق، دسترسی به Hugging Face در طول آزمایش مسدود گردیده است.
برای وظایف کدنویسی:
- نمرات Terminal-Bench با چارچوب عامل پیشفرض (Terminus-2) و تجزیه گر JSON ارائه شده به دست آمد.
- برای سایر وظایف کدنویسی، نتیجه با ابزار ارزیابی داخلی تولید شد. ابزار از SWE-agent ایجاد شد، اما پنجرههای متنی ابزارهای Bash و Edit محدود شدند و پرامپت سیستم برای مطابقت با معنای وظیفه مورد نظر بازنویسی گردید.
- تمام امتیازات گزارششده از وظایف کدنویسی، میانگینی از ۵ اجرای مستقل هستند.
حالت سنگین: حالت سنگین تفکر K2 از یک استراتژی موازی کارآمد استفاده میکند: ابتدا هشت مسیر را بهطور همزمان اجرا میکند، سپس بهطور انعکاسی تمام خروجیها را برای تولید نتیجه نهایی تجمیع میکند. حالت سنگین برای GPT-5 نشاندهنده امتیاز رسمی GPT-5 Pro است.
کوانتیزاسیون بومی INT4
کوانتیزاسیون با بیت پایین روشی مؤثر برای کاهش تأخیر استنتاج و استفاده از حافظه GPU در سرورهای استنتاج در مقیاس بزرگ است. با این حال، مدلهای تفکر از طول رمزگشایی بسیار بالا استفاده میکنند و بنابراین کوانتیزاسیون اغلب منجر به افت قابل توجه عملکرد میشود.
برای غلبه بر این چالش، در مرحله پس از آموزش، آموزش آگاه از کوانتیزاسیون (QAT) را اتخاذ میکنیم و کوانتیزاسیون فقط وزن INT4 را به اجزای MoE اعمال میکند. این به K2 Thinking اجازه میدهد تا از استنتاج بومی INT4 با بهبود سرعت تولید تقریباً ۲ برابر پشتیبانی کند و در عین حال به عملکرد پیشرفته دست یابد. همه نتایج معیار با دقت INT4 گزارش میشوند
چکپوینتها در قالب tensors فشرده ذخیره میشوند که توسط اکثر موتورهای استنتاج جریان اصلی پشتیبانی میشوند. اگر به checkpointها با دقت بالاتر مانند FP8 یا BF16 نیاز دارید، میتوانید برای باز کردن وزنهای int4 و تبدیل به هر دقت بالاتری به مخزن رسمی tensors فشرده مراجعه کنید.
استقرار
میتوانید به API مربوط بهKimi-K2-Thinking از طریق آدرس https://platform.moonshot.ai دسترسی داشته باشید، این API سازگار با OpenAI/Anthropic میباشد.
در حال حاضر، توصیه میشود Kimi-K2-Thinking روی موتورهای استنتاج زیر اجرا شود:
- vLLM
- SGLang
- KTransformers
مثالهای استقرار را میتوانید در راهنمای استقرار مدل به آدرس زیر بیابید.
https://huggingface.co/moonshotai/Kimi-K2-Thinking/blob/main/docs/deploy_guidance.md
استفاده از مدل
تکمیل چت
پس از راهاندازی سرویس استنتاج محلی، میتوانید از طریق نقطه دسترسی چت با آن تعامل داشته باشید
def simple_chat(client: openai.OpenAI, model_name: str):
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant created by Moonshot AI."},
{"role": "user", "content": [{"type": "text", "text": "which one is bigger, 9.11 or 9.9? think carefully."}]},
]
response = client.chat.completions.create(
model=model_name,
messages=messages,
stream=False,
temperature=1.0,
max_tokens=4096
)
print(f"k2 answer: {response.choices[0].message.content}")
print("=====below is reasoning content======")
print(f"reasoning content: {response.choices[0].message.reasoning_content}")دمای توصیه شده برای kimi_k2_thinking برابر با ۱.۰ است. اگر دستورالعمل خاصی لازم نباشد، پیام سیستمی بالا پیشفرض خوبی است.
فراخوانی ابزار
kimi_k2_thinking همان تنظیمات فراخوانی ابزار Kimi-K2-Instruct را دارد.
برای فعال کردن آنها، باید لیست ابزارهای موجود را در هر درخواست ارسال کنید، سپس مدل به طور خودکار تصمیم میگیرد که چه زمانی و چگونه آنها را فراخوانی کند.
مثال زیر فراخوانی یک ابزار آب و هوا را به صورت سرتاسری نشان میدهد:
# Your tool implementation
def get_weather(city: str) -> dict:
return {"weather": "Sunny"}
# Tool schema definition
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Retrieve current weather information. Call this when the user asks about the weather.",
"parameters": {
"type": "object",
"required": ["city"],
"properties": {
"city": {
"type": "string",
"description": "Name of the city"
}
}
}
}
}]
# Map tool names to their implementations
tool_map = {
"get_weather": get_weather
}
def tool_call_with_client(client: OpenAI, model_name: str):
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant created by Moonshot AI."},
{"role": "user", "content": "What's the weather like in Beijing today? Use the tool to check."}
]
finish_reason = None
while finish_reason is None or finish_reason == "tool_calls":
completion = client.chat.completions.create(
model=model_name,
messages=messages,
temperature=1.0,
tools=tools, # tool list defined above
tool_choice="auto"
)
choice = completion.choices[0]
finish_reason = choice.finish_reason
if finish_reason == "tool_calls":
messages.append(choice.message)
for tool_call in choice.message.tool_calls:
tool_call_name = tool_call.function.name
tool_call_arguments = json.loads(tool_call.function.arguments)
tool_function = tool_map[tool_call_name]
tool_result = tool_function(**tool_call_arguments)
print("tool_result:", tool_result)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call_name,
"content": json.dumps(tool_result)
})
print("-" * 100)
print(choice.message.content)تابع tool_call_with_client مسیر انتقال از پرسوجوی کاربر تا اجرای ابزار را پیادهسازی میکند. این مسیر انتقال نیازمند موتور استنتاجی است که از منطق تجزیه ابزار بومی Kimi-K2-Thinking پشتیبانی کند. برای اطلاعات بیشتر، به راهنمای فراخوانی ابزار مراجعه کنید.
https://huggingface.co/moonshotai/Kimi-K2-Thinking/blob/main/docs/tool_call_guidance.md