
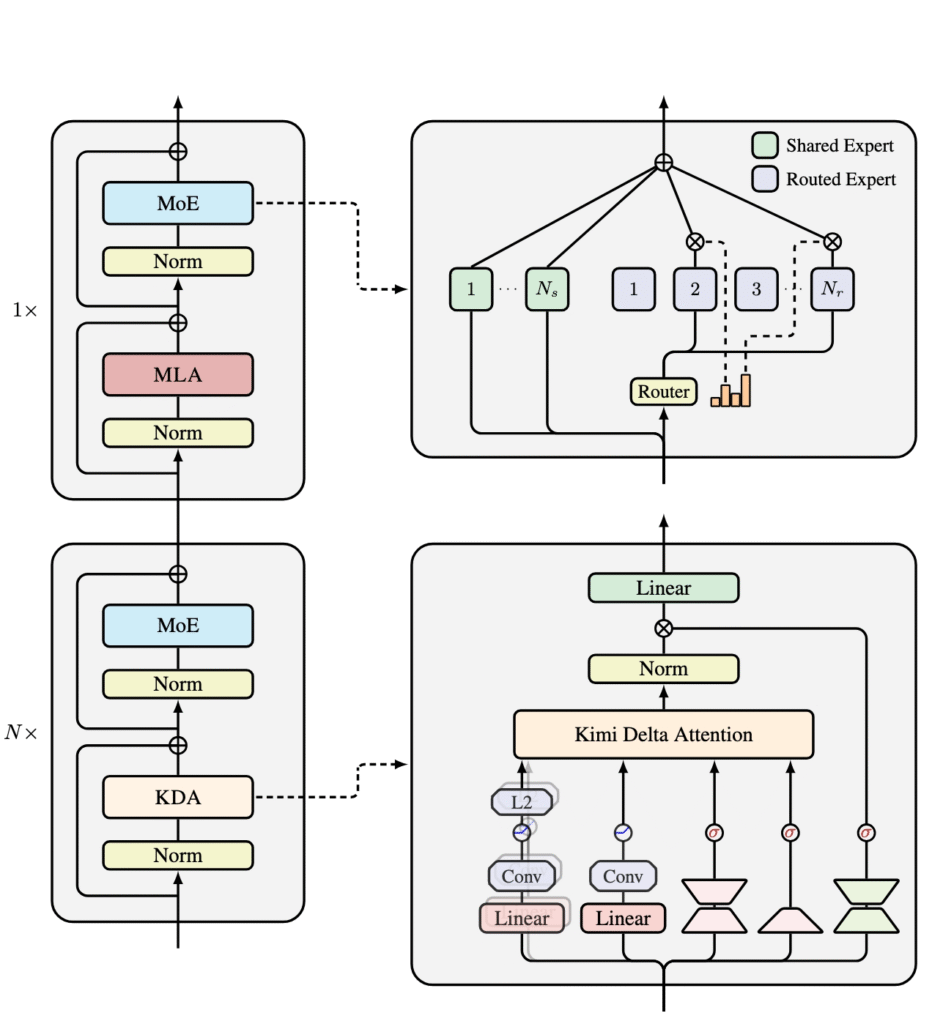
Kimi Linear یک مدل با معماری توجه (attention) خطی ترکیبی است که از روشهای سنتی توجه کامل در زمینههای مختلف، از جمله رژیمهای مقیاسبندی کوتاه، بلند و یادگیری تقویتی (RL)، بهتر عمل میکند. در هسته آن، Kimi Delta Attention (KDA) قرار دارد. نسخهای اصلاحشده از Gated DeltaNet که یک مکانیسم دروازهبندی کارآمدتر را برای بهینهسازی استفاده از حافظه RNN حالت محدود معرفی میکند.
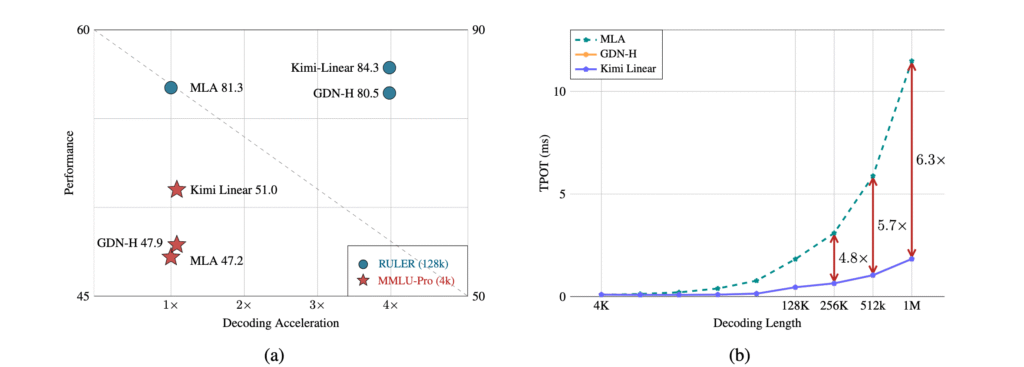
Kimi Linear به عملکرد و کارایی سختافزاری برتر، بهویژه برای وظایف با متون طولانی، دست مییابد. این معماری نیاز به حافظههای نهان بزرگ کلید و مقدار(KV) را تا 75٪ کاهش میدهد و توان رمزگشایی را برای متون تا طول 1 میلیون توکن را تا 6 برابر افزایش میدهد.
هسته KDA در (flash linear attention)FLA متنباز گردیده و دو نسخه از نقاط بازرسی مدل آموزشدیده با توکنهای 5.7T را منتشر شده اند.
| مدل | تعداد کل پارامترها | تعداد پارامترهای فعال | طول متن | رایاپیوند بارگیری |
|---|---|---|---|---|
| Kimi-Linear-Base | 48B | 3B | 1M | https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Base |
| Kimi-Linear-Instruct | 48B | 3B | 1M | https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct |
ویژگیهای کلیدی
توجه دلتای کیمی (KDA): یک مکانیزم توجه خطی که قانون دلتای دروازهای را با دروازهبندی finegrained اصلاح میکند.
معماری ترکیبی: نسبت ۳:۱ KDA به MLA سراسری، استفاده از حافظه را کاهش میدهد و در عین حال کیفیت توجه کامل را حفظ یا از آن پیشی میگیرد.
عملکرد برتر: در انجام وظایف مختلف، از جمله معیارهای متن بلند و سبک یادگیری تقویتی در اجرای آموزش با تعداد توکن ۱.۴T با مقایسههای منصفانه، عملکرد بهتری نسبت به توجه کامل دارد.
توان عملیاتی بالا: رمزگشایی را تا ۶ برابر سریعتر میکند و زمان هر توکن خروجی (TPOT) را به طور قابل توجهی کاهش میدهد.
روش استفاده
استنتاج مدل با استفاده از Hugging Face Transformers
برای استفاده از مدل کیمی خطی محیط اجرای زیر توصیه میشود:
python >= 3.10torch >= 2.6fla-core >= 0.4.0
pip install -U fla-core
نمونه برنامه پایتون
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "moonshotai/Kimi-Linear-48B-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
messages = [
{"role": "system", "content": "You are a helpful assistant provided by Moonshot-AI."},
{"role": "user", "content": "Is 123 a prime?"}
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(inputs=input_ids, max_new_tokens=500)
response = tokenizer.batch_decode(generated_ids)[0]
print(response)استقرار
برای استقرار، میتوانید از جدیدترین vllm برای ایجاد یک endpoint API سازگار با OpenAI استفاده کنید.
vllm serve moonshotai/Kimi-Linear-48B-A3B-Instruct \
--port 8000 \
--tensor-parallel-size 4 \
--max-model-len 1048576 \
--trust-remote-code