
در ادامه خلاصهای از مقاله در 9 بخش تقدیم حضور شما خواهد شد.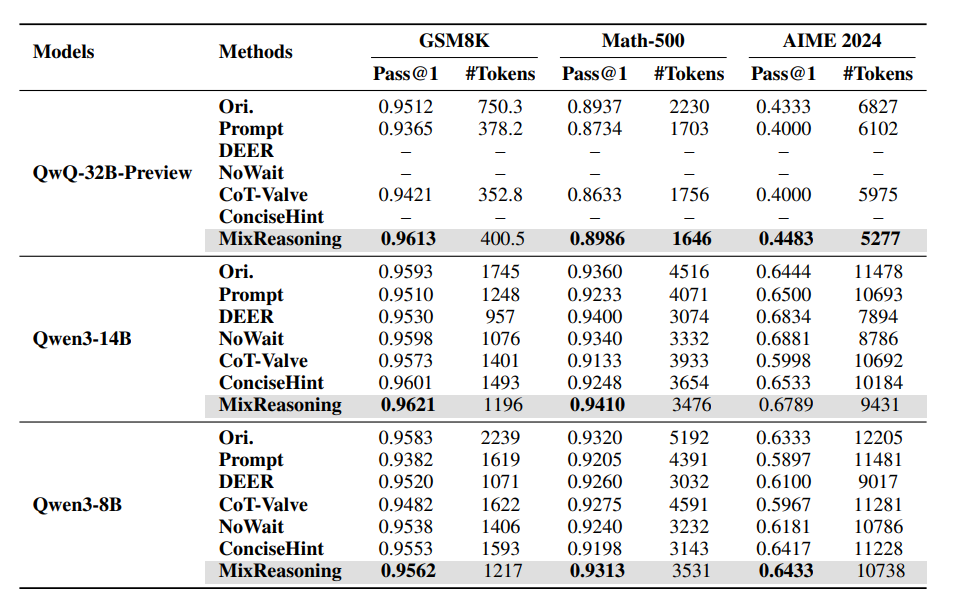
1 — چکیده (مختصر)
MixReasoning پیشنهاد میکند هنگام تولید زنجیرهٔ استدلال (chain-of-thought) در یک پاسخ، بهجای «همیشه تفصیل» یا «همیشه مختصر»، بهصورت پویا بین دو حالت (تفصیلی = thinking و مختصر = non-thinking) جابهجا شود. جابهجایی با استفاده از یک LoRA سبک انجام میشود و نقاط سوئیچ مبتنی بر عدمقطعیت سطح توکن (token-level entropy) است؛ در نتیجه ریزّسازی تفکر فقط در گلوگاههای تصمیمی انجام میشود و ردۀ کلی پاسخها کوتاهتر و قابلخوانشتر میماند، در حالی که دقت حفظ یا بهبود مییابد.
2 — ایدهٔ اصلی
- مشاهدهٔ کلیدی: سختی مراحلِ مختلف در یک زنجیرهٔ استدلال همگن نیست — چند گام تعیینکننده و بسیاری گامِ ساده وجود دارد.
- هدف: «فقط آنجا که لازم است» تفصیلی فکر کن؛ بقیه را خلاصه نگه دار.
- مکانیزم: نگهداری یک مدل پایهی ثابت و یک LoRAِ مختصر که با پارامتر اسکِیلِ (α) قابل تنظیم است تا در زمان اجرا حالتِ مدل از concise↔detailed تغییر کند.
3 — روش (تفصیلی)
3.1 LoRA-محور برای کنترل حالتها
- با fine-tuning سبک LoRA روی نسخههای «کوتاه» رِیشنالها، یک adapter بهدست میآید که مدل را به تولید ریزّسازی کمتر تمایل میدهد.
- در زمان استنتاج، با تغییر ضریب LoRA (α) بین α_low (تفصیلی) و α_high (مختصر) بین حالات سوئیچ میکنند.
3.2 سوئیچ مبتنی بر عدمقطعیت توکنی
- برای هر گام، انتروپی توزیع توکن بعدی H_t محاسبه میشود (نرمالشده). اگر H_t ≥ τ↑ آستانه، پنجرهٔ نامطمئن W_t = [t−B, t+F] باز شده، از مرز چپ بازگردانی شده و آن بازه با حالت تفصیلی (α_low) دوباره رِژنِریت میشود.
- برای جلوگیری از نوسان، از هیسترزیس با آستانهٔ پایینتر τ↓ استفاده میشود؛ یعنی تا زمانی که H_t > τ↓ در حالت تفصیلی میمانند. این دو پارامتر (τ و اندازهٔ پنجره) نقش «نوبتکنترلِ بودجه» را بازی میکنند.
3.3 بازاستفادهٔ KV-cache و هزینهٔ Prefill
- چون فقط LoRA تغییر وضعیت میدهد و مدل پایه ثابت میماند، میتوان کش توجه (KV) را تا حد زیادی بازاستفاده کرد و تنها بخش کوچکِ پیشپُر (prefill) برای بازهٔ تازهٔ تفصیلی محاسبه میشود؛ بنابراین هزینهٔ عملیاتی سوئیچ محدود و کنترلشدنی است. افزون بر این، اگر LoRA فقط روی MLPها اعمال شود (نه K/V attention)، بازاستفادهٔ کاملِ KV ممکن است.
4 — تنظیمات آزمایشی
- مدلها: QwQ-32B-Preview، Qwen-3-14B، Qwen-3-8B.
- بنچمارکها: GSM8K (ریاضیات پایه)، Math-500، AIME24 (مسائل رقابتی).
- مقایسه با چند baseline شامل: Long CoT اصلی و روشهای فشردهسازی طولی (Prompting، CoT-Valve، DEER، NoWait، ConciseHint).
5 — نتایج کلیدی
- بهبود مرز دقت–کارایی: MixReasoning معمولاً طولِ زنجیرهها را بهطور چشمگیر کاهش میدهد و در بسیاری موارد دقت را نیز افزایش یا لااقل حفظ میکند. نمونهٔ شاخص: روی QwQ-32B در GSM8K میانگین توکنها از 750.3 → 400.5 کاهش یافت و دقت از 95.12% → 96.13% افزایش یافت. روی سایر مدلها و دیتاستها نیز کاهش توکن و دقتِ برابر یا بهتر گزارش شده است.
- کنترلپذیری: دو «ولوم» زمان اجرا (آستانهٔ عدمقطعیت τ↑ و اندازهٔ پنجره W) امکان تعیین صریح میزان پوشش حالت تفصیلی و در نتیجه تعادل دقت/بودجه را فراهم میکنند.
- نتیجهٔ عملیاتی: در مقایسه با روشهای فشردهسازیِ یکنواخت، MixReasoning در نمودار دقت-درمقابل-توکن (Pareto) جلوتر قرار میگیرد؛ همچنین گاهی یک روند U-شکل نشان میدهد که زنجیرههای خیلی طولانی میتوانند عملکرد را بدتر کنند و کوتاهسازی هوشمندانه سودبخش است.
6 — یافتههای اصلی مقاله
- بخش بزرگی از زنجیرههای طولانی زائد است و میتوان با انتخاب محلیِ نقاطِ تفصیلی، هزینه را کاهش داد.
- LoRA سبک راهکار عملی برای الحاق حالت «مختصر» به مدل پایه است و با تغییر ضریب در زمان اجرا میتوان بین حالات جابهجا شد بدون فرِتینگ (forgetting) مدل پایه.
- توزیع انتروپی توکنها سیگنال درونمدلی مفیدی برای شناسایی گلوگاههای تصمیمی است؛ با بازتولید پنجرهایِ آن نقاط، میتوان تفصیلیسازی را متمرکز کرد.
7 — محدودیتها و کارهای آینده
- کنترل فعلی مبتنی بر آستانه و انتروپی «آموزشندیده» است و ممکن است نسبت به کالیبراسیون یا وابستگیهای غیربومی حساس باشد. نویسندگان پیشنهاد میکنند سیاستهای یادگرفتهشده (RL یا imitation learning) یا ترکیب با routingِ سطح-مسئله و speculative decoding را بررسی کنند.
8 — جزئیات پیادهسازی
- LoRA روی دادههای GSM8K (train) با رنک 2 و α=8 آموزش داده شده؛ batch=64، تا 10 اپوک؛ آموزش روی 4×A100-80GB انجام شده.
- برای گزارشها از flexible-match metric استفاده شده (استخراج مقدار داخل \boxed{} یا در غیاب آن آخرین عدد پاسخ). حداکثر توکنها نیز بسته به مدل/بنچمارک متفاوت تنظیم شده است.
9 — پیام نهاییِ کوتاه
MixReasoning راهکار عملی و قابلپیادهسازیای برای «فکر کردن جایی که اهمیت دارد» ارائه میدهد: با سوئیچ LoRA در زمان اجرا و تصمیمگیری بر اساس انتروپی توکن، زنجیرههای استدلال کوتاهتر، خواناتر و در عمل کارا میشوند، بدون نیاز به سروِ چند مدل یا رِتِرِینِ کاملِ وزنها.
دانلود کامل مقاله: